12數據庫
發(fā)布時間:
1 知識點匯總2 知識點詳解關系型數據庫Oracle功能強大,缺點貴MySQL互聯網行業(yè)中最流行的數據庫MariaDBMySQL的分支,由開源社區(qū)維
1 知識點匯總

2 知識點詳解
關系型數據庫
- Oracle
- 功能強大,缺點貴
- MySQL
- 互聯網行業(yè)中最流行的數據庫
- MariaDB
- MySQL的分支,由開源社區(qū)維護
- PostgreSQL
- 類似于Oracle的多進程模型,可支持高并發(fā)的應用場景,幾乎支持所有SQL標準,適合嚴格的企業(yè)應用場景
NoSQL(Not Only SQL)
- Redis
- 適用于數據變化快,數據大小可預測的場景
- MongoDB
- 基于分布式文件存儲的數據庫
- 將數據存儲為一個文檔,數據結構由鍵值對組成
- 適用于表結構不明確,數據結構不斷發(fā)生變化的場景
- 不適合有事務和復雜查詢的場景
- Hbase
- 是在hdfs(Hadoop Distributed File System hadoop分布式文件系統(tǒng))中分布式面向列的數據庫,類似于Google的Bigtable
- 可提供快速隨機訪問海量結構化數據,在表中由行排序,一個表中有多個列族,每個列族有任意數量的列
- 依賴于hdfs,可以實現海量數據的可靠存儲,適用于數據量大,寫多讀少,不需要復雜查詢的場景
- Cassandra
- 高可靠大規(guī)模分布式存儲系統(tǒng)
- 支持分布是的結構化K-V存儲
- 以高可用為主要目標
- 適合寫多場景,簡單查詢,不適合數據統(tǒng)計
- Pika
- 提供大容量類Redis的存儲服務
- 兼容Redis的五種數據結構的大部分命令
- 使用磁盤存儲,解決Redis存儲成本問題
NewSQL
- TiDB
- 開源分布式關系型數據庫
- 幾乎完全兼容MySQL
- 支持水平彈性擴展,ACID事務,標準SQL,MySQL語法和MySQL協議
- 具有數據強一致性的高可用性
- 既適合在線事務處理,也適合在線分析處理
- OceanBase
- 螞蟻金服所有,滿足金融級數據可靠性以及數據一致性要求的數據庫系統(tǒng)
- 以商業(yè)化不再開源
數據庫范式
范式級別越高,對數據表要求的越嚴格
- 第一范式(最低)
- 要求表中的字段不可再拆分
- 第二范式
- 在滿足第一范式的基礎上,要求每條記錄由主鍵唯一區(qū)分,記錄中的所有屬性都依賴與主鍵
- 第三范式
- 在滿足第二范式的基礎上,要求所有屬性直接依賴于主鍵,不允許間接依賴
- 巴斯-科德范式(一般滿足至此即可)
- 在滿足第三范式的基礎上,要求聯合主鍵的各字段之間互不依賴
事務分類
- 扁平事務:所有操作都在同一層次(日常使用最多).缺點:不能提交事物的某一部分
- 帶保存點的扁平事務:在事務中插入保存點,失敗回滾時,可回滾至任意保存點,而不是回滾整個事務
- 鏈事務:可看作上一事務的變種,事務提交時會將上下文隱式傳遞給下一個事務,事務失敗時,回滾至最近的事務
- 嵌套事務:由上層事務和子事務組成,類似樹形結構.頂層事務負責邏輯處理,子事務負責具體操作.子事務提交后需等待上層事務提交才算完成,若上層事務回滾,則所有子事務回滾
- 分布式事務:分布式環(huán)境中的扁平化事務
- XA規(guī)范:保證強一致性的剛性事務方案
- 兩段式提交
- 需要事務協調者保證,事務參與者都完成第一階段的事務準備階段.當都準備完成則通知事務參與者進行下一階段事務.(類似于Java中的countdownlatch和cyclicbarruer)
- 在一個進程發(fā)生故障時,會有較長時間的阻塞
- 三段式提交
- 增加PreCommit環(huán)節(jié),減少兩段式提交中的阻塞時間
- TCC:滿足最終一致性的柔性事務方案
- 對每個操作都注冊確認和補償操作
- try階段:檢測業(yè)務系統(tǒng),預留資源
- confirm階段:確認提交
- cancel階段:業(yè)務執(zhí)行錯誤時執(zhí)行回滾,釋放預留資源
- 消息事務:消息一致性方案
- 將本地操作與消息發(fā)送封裝在一個事務中,保證本地操作與消息發(fā)送要么都成功,要么都失敗
- 下游應用收到收到消息執(zhí)行對應操作
MySQL
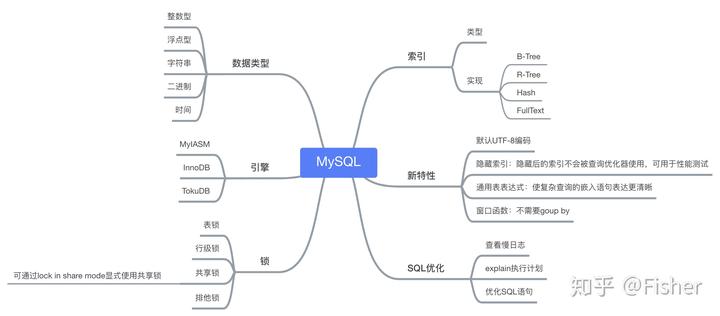
索引
可大幅增加數據庫的查詢性能,適合讀多寫少的場景
代價:需要額外空間保存索引,插入更新刪除時,由于更新索引增加額外的開銷
- 索引類型
- 唯一索引
- 索引列中的值唯一,允許出現空值
- 主鍵索引
- 特殊的唯一索引不允許出現空值
- 普通索引
- 索引列中的值不唯一
- 聯合索引
- 多個列按順序組成索引,相同列不同順序為不同索引
- 全文索引
- 只能在char varchar text等類型使用
- 索引實現
- B-Tree
- 最常用
- R-Tree
- 用于處理多維數據的數據結構,可對地理數據進行空間索引
- Hash
- 效率比B-Tree高,不支持范圍查找,排序等功能
- FullText
- 適用于全文索引
MySQL調優(yōu)
- 表結構與索引
- 分庫分表,讀寫分離
- 為字段選擇合適的數據類型
- 將字段多的表分揀成多個表,增加中間表
- 混合范式與反范式,適當冗余
- 為查詢創(chuàng)建必要索引,但避免濫用
- 盡可能地是以哦那個NOT NULL
- SQL語句優(yōu)化
- 尋找最需要優(yōu)化的語句:分析慢查詢日志
- 使用頻繁或效率最低的
- 利用查詢工具:explain,profile
- 避免使用SELECT *, 只取需要的列
- 盡可能使用prepared statements
- 使用索引掃描來排序
- MySQL參數優(yōu)化
- 硬件及系統(tǒng)配置
從1到4優(yōu)化成本增加,優(yōu)化效果降低
考察點
- 了解數據庫的基本原理,數據庫的特點
- 理解數據庫事務的ACID特性和隔離級別
- 掌握常用的MySQL語句和常用函數
- 了解MySQL數據庫不同引擎多的特點以及不同類型的索引實現
3 面試題整理
- 數據庫查詢速度慢,如何優(yōu)化?
- 什么情況會導致索引失效?
- 數據庫事務有哪些特征?事務的隔離級別有哪幾種?
- 如何對 SQL 語句進行優(yōu)化?






