GPT2
Language Models are Unsupervised Multitask LearnersGPT2 - TZ blog語言模型是一個無監督的多任務學習器使用webText數據集訓
Language Models are Unsupervised Multitask Learners
GPT2 - TZ blog
語言模型是一個無監督的多任務學習器
使用webText數據集訓練15億參數的GPT2,zero-sho在多個任務上取得了SOTA的結果。并且在WebText數據上仍然欠擬合(underfits)
語言模型的容量對zero shot任務的遷移是很重要的,并且增加容量可以以對數線性方式提高模型性能。模型參數大小是x軸,性能是y軸。
作者認為:單領域數據集上單任務的訓練是當前模型泛華能力不足的原因,多任務學習根據元學習角度,每一個(dateset,objective)是從datasets和objects的分布中采樣,仍然需要較多的目標訓練數據。
預訓練和監督微調的方法組合也是一個方法,但是仍然是監督學習,作者展示了語言模型可以在zero-shot下執行下游任務,不需要參數或架構的修改。
Approach
單任務可以用一個條件分布表示 $p(output|input)$ 多任務$p(output|input, task)$,對于不同task的處理之前通過設計特殊的encoder 和decoder,通過模型架構來處理多任務。但是語言也提供了靈活的方式來標識不同的task。
作者通過語言模型zero-shot在多任務的性能的表現,來衡量語言模型是否是一個無監督多任務學習器。
數據
盡可能大和多樣化(多領域)
Comon Crawl 存在質量問題。“內容大多難以理解”
從社交媒體Reddit抓取outbound links,有4500萬個鏈接,清理去重后有800萬個文檔,總40GB的文本。(刪除了Wikipedia的文檔。因為是通用數據源可能造成訓練和測試數據的重疊。)
數據輸入
需要有一個詞匯表,來包含130000個unicode字符。(Unicode 13.0共有143859個字符),這比BPE通用的32k和64k詞表大太多。byte bpe僅僅需要256的vocab大小。16*16
采用BPE,作者發現在BPE 詞表中有很多變體,如dog為dog. dog! dog? 這因為bpe使用頻率的啟發式貪心算法導致suboptimal merges。
所以作者組織BPE合并跨字符類比的字符。并且為空格添加了一個exception
(暫不知操作是什么)
提高壓縮效率,添加最少的單詞碎片。
這樣使模型在任何數據集上都可以進行模型評估。
模型
詞表大小 50257
batch size 512, context sieze 1024
實驗

訓練了四個模型。模型參數大小的差距是log近似 log(parameters)約等于1,每個模型的學習率都是手動調整的以至于在5%webtext保留數據集上獲得最好的困惑度。所有模型仍然欠擬合,

Children's Book Test(CBT) 檢查LM在不同詞類的表現,命名實體,名詞,動詞介詞。將模型完形填空的準確率作為評價指標。
LAMDADA:系統對文本中遠程依賴建模的能力,預測句子的最后一個單詞。
GPT2的錯誤預測情況下大多是句子的延續而不是句子結尾的最后一個單詞。表明LM沒有使用單詞必須是結尾的約束條件。添加一個停用詞過濾會將準確率從
52.66%提升到63.24%。
Winograd Schema Challenge:衡量系統解決文本歧義的能力來衡量系統執行常識推理的能力。
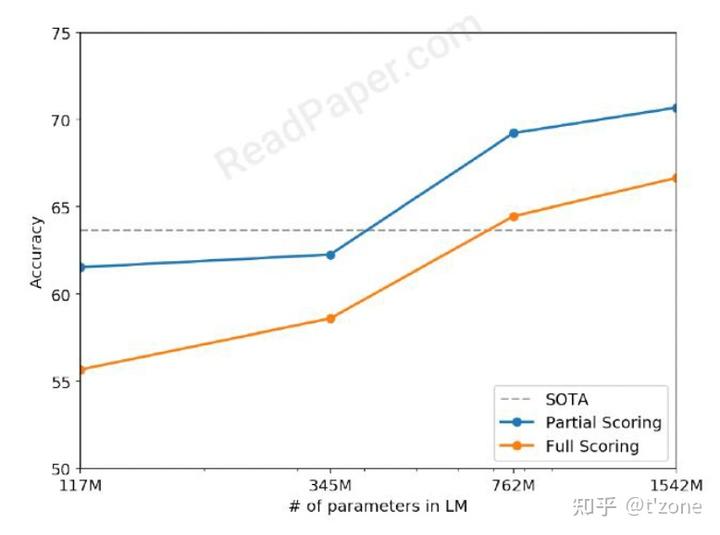
CoQA Conversation Question Answering:
GPT2 在開發集上55 F1(zero shot)。SOTA 是bert進行監督學習 89F1. 從錯誤預測的數據中作者發現,GPT2經常使用簡單的,基于啟發式的檢索方法。例如用文檔中的名字回答Who問題。
CNN and Daily Mail dataset [Summarization]
為了誘導模型摘要的能力,在文檔之后添加文本 TL;DR,使用top-k隨機抽樣,k=2,減少重復并估計更抽象的摘要。
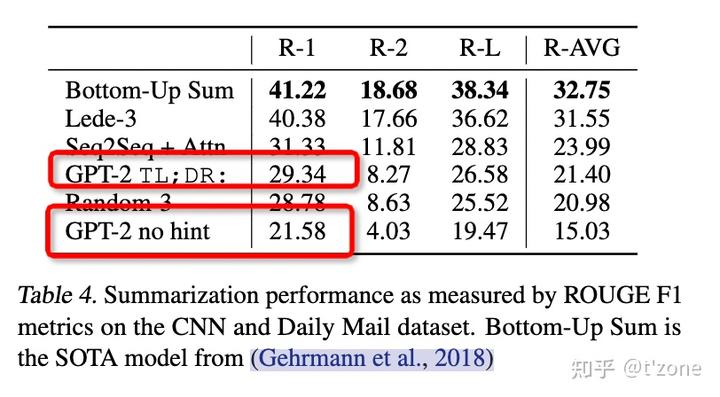
當任務提示移出后,GPT2的指標下降了6.4,這證明可以使用自然語言調用模型針對特定任務的行為。
WMT14-En-Fr
wmt14-en-fr :GPT2 5BLEU,
Wmt14-fr-en: GPT2 11.5 BLEU. 得益于英文的語言模型。 最好的無監督機器翻譯方法 BLUE是33.5 。差的還比較多。
Question-answer
SQUAD: GPT2 準確回答了4.1%的準確率。最小的模型準確率低于1%。(Who,What,Where),GPT2在最小信息的1%的數據上有63.1%準確率
泛化與記憶
基于8-gram重疊作為重復句子,判斷webtext數據和其他測試數據集的重復率
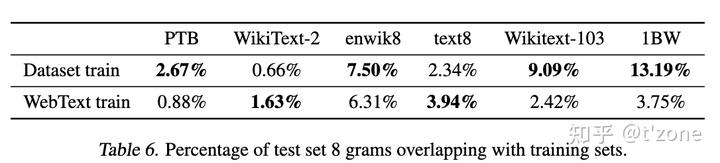
作者建議在新的NLP數據集上創建訓練或測試拆分期間,基于n-gram重復的驗證是有必要的。
下圖可以看出,模型仍然是欠擬合。

相關工作
Jozefowicz et al. (2016) 在10億word上訓練RNN語言模型。
語言模型有趣的功能Karpathy et al. (2015). ,line-width tracking and quote/comment detection
(Ramachandran et al., 2016) 證明了seq2seq模型受益于預訓練語言模型作為編碼器和解碼器的初始化。
(Wolf et al., 2019) (Dinan et al., 2018) LM pre-training 在對話和困難生成任務上進行微調也有很幫助
討論
雖然作為研究結果具有啟發性,但是實際應用,GPT2的零樣本性能仍遠未可用。
尚不清楚GPT2微調的上限。
并且不清楚GPT2的額外訓練數據和容量是否能夠克服BERT所展示單向表示的低效率(Devlin et al., 2018).2






