GPT-4的多模態(tài)能力是如何實(shí)現(xiàn)的?
相比ChatGPT,OpenAI最新發(fā)布的GPT-4不僅增強(qiáng)了原來(lái)的文本生成能力,還支持了多模態(tài)能力。GPT-4不僅支持純文本輸入,還支持輸入圖像,當(dāng)
相比ChatGPT,OpenAI最新發(fā)布的GPT-4不僅增強(qiáng)了原來(lái)的文本生成能力,還支持了多模態(tài)能力。GPT-4不僅支持純文本輸入,還支持輸入圖像,當(dāng)輸入圖像時(shí),GPT-4可以生成理解圖像的文本回答。下面是GPT-4技術(shù)報(bào)告中的一個(gè)具體示例,這里給定一個(gè)圖像,模型能夠準(zhǔn)確找到圖像中不正常的現(xiàn)象,可見(jiàn)GPT-4的圖像理解能力還是非常強(qiáng)的。

雖然OpenAI展示了GPT-4的視覺(jué)理解能力,但是在技術(shù)報(bào)告中并沒(méi)有給出實(shí)現(xiàn)的具體細(xì)節(jié),而且這項(xiàng)功能還處于研究中,并沒(méi)有對(duì)外開(kāi)放。我想大部分人會(huì)對(duì)GPT-4的多模態(tài)能力比較感興趣,因?yàn)橐雽?shí)現(xiàn)AGI(通用人工智能),AI必須要掌握多模態(tài)理解能力。雖然OpenAI沒(méi)有給出技術(shù)細(xì)節(jié),但是其實(shí)最近已經(jīng)有一些工作嘗試實(shí)現(xiàn)類似的能力,比如最近剛開(kāi)源的MiniGPT-4。這篇文章我們將簡(jiǎn)單講解四個(gè)相關(guān)的工作,看看它們是如何在語(yǔ)言模型中嵌入視覺(jué)理解能力的,這4個(gè)工作是:
- Flamingo: a Visual Language Model for Few-Shot Learning
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
- LLaVA: Visual Instruction Tuning
這里除了DeepMind的Flamingo,其它3個(gè)工作都是開(kāi)源的,其中后面兩個(gè)MiniGPT-4和LLaVA是最近的工作。 在講解這4個(gè)工作之前,其實(shí)我們也可以先簡(jiǎn)單想一下具體的實(shí)現(xiàn)思路,注意這里我們不是直接訓(xùn)練一個(gè)多模態(tài)模型(目前也沒(méi)有那么大的多模態(tài)數(shù)據(jù)來(lái)訓(xùn)練,我想OpenAI也不是那么做的),而是在已經(jīng)預(yù)訓(xùn)練好的語(yǔ)言大模型中引入圖像理解能力。所以這里大概要需要這兩點(diǎn):
- 首先,我們必須得有個(gè)預(yù)訓(xùn)練好的視覺(jué)模型,它可以用來(lái)提取圖像的語(yǔ)義特征,而且圖像的特征能夠很好地嵌入預(yù)訓(xùn)練好的語(yǔ)言模型中,我能想到的最合適的模型就是OpenAI所提出的CLIP,CLIP的image encoder能夠輸出和文本對(duì)其的特征。
- 然后,我們要有一個(gè)包含圖像和文本的多模態(tài)數(shù)據(jù)集,這個(gè)數(shù)據(jù)集用來(lái)finetune模型,由于這里我們只是支持圖像輸入,而本身的任務(wù)還是文本生成,所以訓(xùn)練損失還是采用語(yǔ)言模型的language modeling loss,即根據(jù)前面的輸入預(yù)測(cè)下一個(gè)token。
我們將要介紹的這4個(gè)工作其實(shí)也主要來(lái)圍繞著上面兩點(diǎn)來(lái)進(jìn)行實(shí)現(xiàn)的。
Flamingo
DeepMind的Flamingo這個(gè)工作是在22年4月發(fā)表的,也算是比較早的工作。Flamingo模型是一個(gè)可以輸入圖像(也支持視頻)和文本來(lái)生成文本的多模態(tài)模型。它的模型架構(gòu)如下所示:
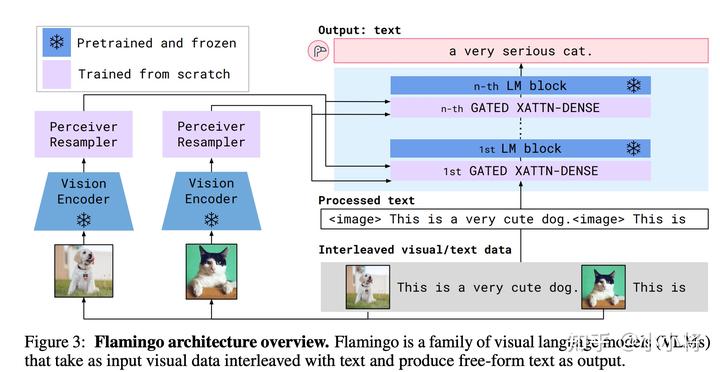
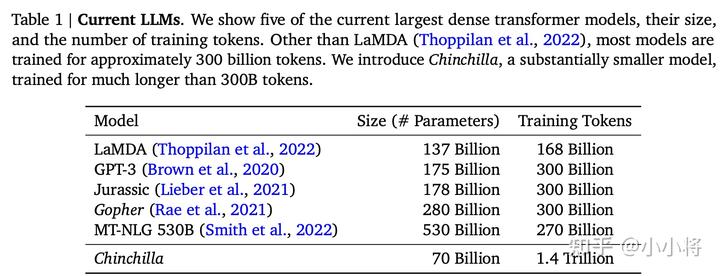
首先,F(xiàn)lamingo模型是建立在一個(gè)預(yù)訓(xùn)練好的語(yǔ)言模型基礎(chǔ)上的,它這里選擇的模型是DeepMind之前所提出的Chinchilla,最大的Chinchilla模型參數(shù)量雖然只有70B,但是訓(xùn)練的Tokens數(shù)量卻比GPT-3多:
然后,F(xiàn)lamingo模型又引入了一個(gè)預(yù)訓(xùn)練好的Vision Encoder,這個(gè)視覺(jué)模型采用的是DeepMind在21年所提出的NFNet-F6(其實(shí)是沒(méi)有Normalization的ResNet),不過(guò)這個(gè)模型是采用CLIP對(duì)比損失在圖像文本對(duì)數(shù)據(jù)集上預(yù)訓(xùn)練的,所以它提出的特征其實(shí)和文本是有一定對(duì)齊的,這里采用模型最后一個(gè)stage的輸出的特征,它是一個(gè)2D(有空間結(jié)構(gòu))特征,可以將它展開(kāi)為1D的序列特征。前面說(shuō)過(guò),F(xiàn)lamingo模型也是支持視頻輸入的,對(duì)于視頻數(shù)據(jù),可以采用Vision Encoder逐幀來(lái)提取特征,可以得到一個(gè)3D特征,然后加上一個(gè)可學(xué)習(xí)的temporal embeddings(編碼時(shí)間維度),最后也可以展開(kāi)為1D的序列特征。雖然圖像和視頻最終都得到了1D序列,但是它們的長(zhǎng)度是不同的,為了解決這個(gè)問(wèn)題,DeepMind又引入了一個(gè)新的模塊Perceiver Resampler:
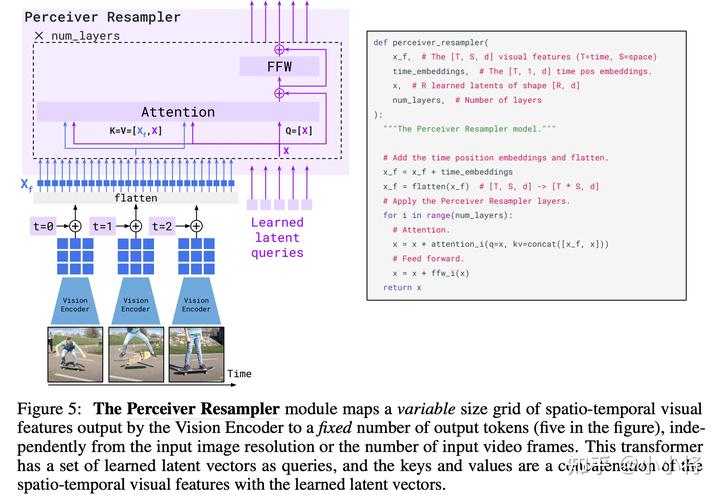
這個(gè)Perceiver Resampler可以接受變長(zhǎng)度的視覺(jué)特征,但是最終輸出的是固定長(zhǎng)度的特征,其實(shí)現(xiàn)思路也很簡(jiǎn)單,首先我們預(yù)定義固定長(zhǎng)度的latent input queries,然后通過(guò)對(duì)Vision Encoder提取的特征進(jìn)行cross-attention來(lái)提取固定長(zhǎng)度的視覺(jué)特征。 那么如何將視覺(jué)特征嵌入語(yǔ)言模型中呢?DeepMind這里采用的方式是cross-attention,這是一種最常用的方法了。不過(guò),這里所引入的是GATED XATTN-DENSE layers,它和常規(guī)的cross-attention略有不同:
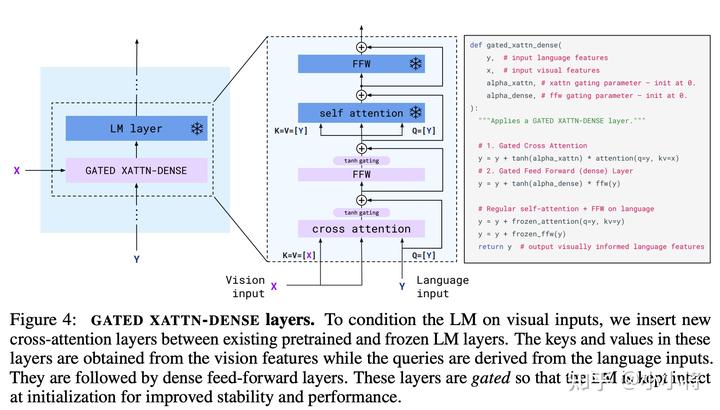
如上所示,可以看到這里是一種gated cross-attention,這里的alpha_xattn是一個(gè)可以學(xué)習(xí)的參數(shù),初始為0,那么初始模型和原來(lái)的語(yǔ)言模型輸出是一樣的。
Flamingo模型共包含4個(gè)部分:預(yù)訓(xùn)練好的LM和Vision Encoder,以及新引入的Perceiver Resampler和gated cross-attention layers,訓(xùn)練過(guò)程前兩個(gè)部分是凍結(jié)的,只有后兩個(gè)模塊是訓(xùn)練的。 訓(xùn)練Flamingo模型所采用的訓(xùn)練數(shù)據(jù)集是文本和圖像交疊的多模態(tài)數(shù)據(jù)集,如下圖所示:

這其實(shí)包含3個(gè)部分,首先是M3W數(shù)據(jù)集,這是從互聯(lián)網(wǎng)上收集的圖像和文本交疊的數(shù)據(jù)集,上圖的第3個(gè)是一個(gè)具體的示例。另外兩部分是圖像-文本對(duì)和視頻-文本對(duì),它們也可以構(gòu)造成和M3W一樣的格式,如上圖的第1個(gè)和第2個(gè)。由于樣本中可能包含不同數(shù)量的圖像(或者視頻),這里為了使得Flamingo模型適配這樣的可變輸入,每個(gè)text token其實(shí)只cross-attention一個(gè)圖像/視頻特征:只用它前面最近的圖像/視頻,如下所示:

Flamingo模型主打的是它的few-shot能力,就是給定一些任務(wù)示例,然后可以對(duì)同樣的任務(wù)做出回答,其實(shí)這個(gè)和GPT-3采用同樣的思路,即構(gòu)建prompt模版,如下所示:

下面是一些具體的示例:
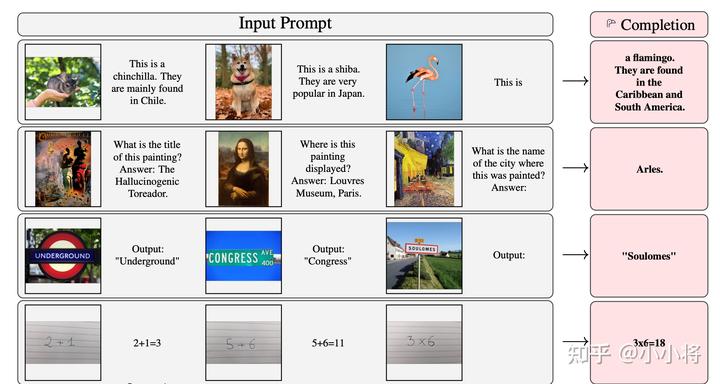
除了這種few-shot能力,其實(shí)Flamingo模型也有一定的zero-shot能力,如下所示:

同時(shí),F(xiàn)lamingo模型也可以進(jìn)行多輪對(duì)話:

雖然看起來(lái)Flamingo模型設(shè)計(jì)的比較復(fù)雜,但是它卻是一個(gè)全能型選手,支持多圖片輸入,而且也支持視頻。不過(guò)DeepMind并沒(méi)有將這個(gè)模型開(kāi)源,但是最近LAION實(shí)現(xiàn)了一個(gè)開(kāi)源版本的OpenFlamingo,它的語(yǔ)言模型采用的是LLaMA,而Vision Encoder采用的是CLIP ViT/L-14,同時(shí)它們也構(gòu)建了圖像和文本交疊的數(shù)據(jù)集Multimodal C4來(lái)訓(xùn)練模型。
BLIP-2
BLIP-2是23年1月份的工作,也算是比較新的工作,我個(gè)人覺(jué)得它應(yīng)該是借鑒了DeepMind的Flamingo模型,它也是采用了一個(gè)預(yù)訓(xùn)練好的語(yǔ)言模型和視覺(jué)模型,并設(shè)計(jì)了一個(gè)Q-Former模塊來(lái)連接兩者,整體結(jié)構(gòu)如下所示:
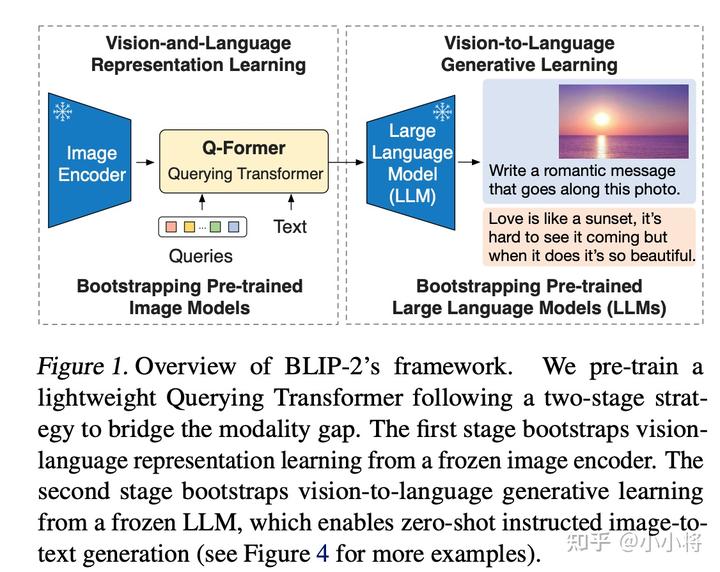
BLIP-2的Q-Former模塊和Flamingo模型的Perceiver Resampler模塊有點(diǎn)類似,它也是用來(lái)從Image Encoder提取的視覺(jué)特征中得到固定長(zhǎng)度的特征。Q-Former模塊包含兩個(gè)transformer子模塊,它們是共享self-attention層的,如下圖所示:
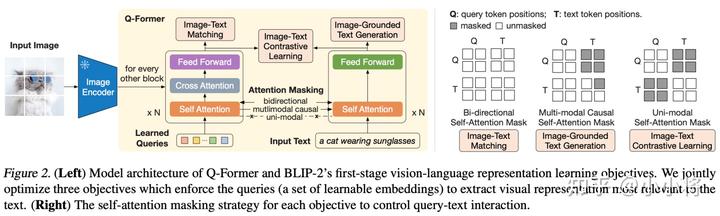
第一個(gè)transformer模塊是一個(gè)image transformer模型,這里預(yù)先定義了固定數(shù)量(論文中設(shè)定為32)的learned queries作為輸入,然后在transformer模塊中引入cross-attention來(lái)和Image Encoder得到的特征進(jìn)行交互。第二個(gè)transformer模塊是一個(gè)text transformer模型,輸入是text,它與image transformer共享self-attention層。Q-Former采用輕量級(jí)的transformer,具體的是采用188M參數(shù)的BERT-base,也使用了BERT預(yù)訓(xùn)練權(quán)重進(jìn)行初始化。 與Flamingo模型不同的是,Q-Former模塊采用了兩階段的訓(xùn)練策略來(lái)將這個(gè)模塊提取的特征嵌入到預(yù)訓(xùn)練好的LM模型中。第一個(gè)階段主要是從Image Encoder中的特征中學(xué)習(xí)到與文本對(duì)齊的固定長(zhǎng)度特征,這個(gè)階段的訓(xùn)練是基于圖像-文本對(duì)數(shù)據(jù)集來(lái)進(jìn)行訓(xùn)練的。訓(xùn)練采用了3種優(yōu)化目標(biāo):
- Image-Text Contrastive Learning (ITC):這個(gè)優(yōu)化目標(biāo)采用對(duì)比損失來(lái)對(duì)齊圖像特征和文本特征,這里的文本特征采用的是text transformer得到的CLS token對(duì)應(yīng)的特征,它首先和每個(gè)query特征計(jì)算特征相似度,并匹配到相似度最大的那個(gè)query特征。注意,這里采用uni-modal self-attention mask,即保證圖像和文本在self-attention互相不可見(jiàn),以防止信息泄露。
- Image-grounded Text Generation (ITG):這個(gè)優(yōu)化目標(biāo)是給定圖像特征作為condition來(lái)生成文本,這個(gè)采用multi-modal causal self-attention mask,即query可以互相attention,但是不attention text,而每個(gè)text token可以attention所有的query,并attention它之前的text tokens。
- Image-Text Matching (ITM):采用一個(gè)二分類任務(wù)來(lái)對(duì)圖像和文本特征進(jìn)行細(xì)粒度的對(duì)齊,具體是判定一個(gè)image-text對(duì)是不是匹配的,這里采用的是bi-directional self-attention mask,即所有的query和text token都可以互相attention。
總之,這個(gè)階段其實(shí)是希望通過(guò)這三個(gè)多模態(tài)優(yōu)化目標(biāo)讓Q-Former模塊從Image Encoder提取到和文本相關(guān)的固定長(zhǎng)度特征。其實(shí)BLIP-2所采用的Image Encoder是OpenAI的CLIP-L/14或EVA-CLIP ViT-G/14(采用ViT倒數(shù)第2層輸出),它們輸出的特征本身就是多模態(tài)特征,所以第一階段的對(duì)齊可以看成是一個(gè)增強(qiáng)。 BLIP-2的第二個(gè)階段是將Q-Former提取的圖像特征和預(yù)訓(xùn)練好的LLM連接在一起,這里不是像Flamingo模型那樣采用cross-attention,而是直接采用一個(gè)全連接層將特征映射到LLM的特征空間(和LLM的text embeddings同維度),這個(gè)映射后的特征可以看成是 soft visual prompts,它可以像文本一樣直接輸入到LLM模型中,如下圖所示:
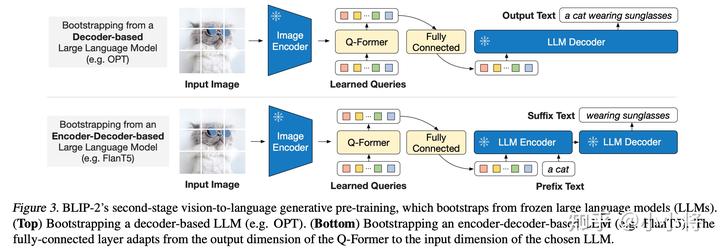
BLIP-2共實(shí)驗(yàn)了兩種LLM模型:第一種是decoder-based LLM,這里選擇的是Meta開(kāi)源的OPT(開(kāi)源版本GPT);第二種是 encoder-decoder-based LLM,這里選擇的是谷歌開(kāi)源的FLAN-T5,它是在T5模型基礎(chǔ)上進(jìn)行了instruction finetuning(見(jiàn)Scaling Instruction-Finetuned Language Models)。對(duì)于decoder-based LLM,這個(gè)階段的finetune是直接language modeling loss:根據(jù)soft visual prompts來(lái)生成文本;而對(duì)于encoder-decoder-based LLM,則是采用 prefix language modeling loss :將文本拆分成兩個(gè)部分,第一部分作為prefix text接在soft visual prompts后面,然后送入LLM Encoder,LLM Decoder將據(jù)此來(lái)生成第二部分文本。注意,這個(gè)階段的訓(xùn)練也是對(duì)凍結(jié)LLM的,訓(xùn)練數(shù)據(jù)也是采用圖像文本對(duì)。 相比較Flamingo,BLIP-2的訓(xùn)練是直接在圖像文本對(duì)數(shù)據(jù)集上訓(xùn)練的,圖像文本對(duì)數(shù)據(jù)集是先收集 129M 圖像,然后采用BLIP的caption模型生成對(duì)應(yīng)的文本描述(每個(gè)圖像生成兩個(gè)top captions)。 但是BLIP-2也能夠?qū)崿F(xiàn)zero-shot的生成,你只需要將text prompt接在soft visual prompts后面就可以了,下面是一些具體的示例:

論文中比較了BLIP-2在Zero-shot VQA 任務(wù)上的性能,如下表所示,這里 BLIP-2 ViT-G FlanT5XXL 的性能要超過(guò) Flamingo80B。另外從表中的對(duì)比結(jié)果,我們也可以看到:a stronger image encoder or a stronger LLM both lead to better performance。
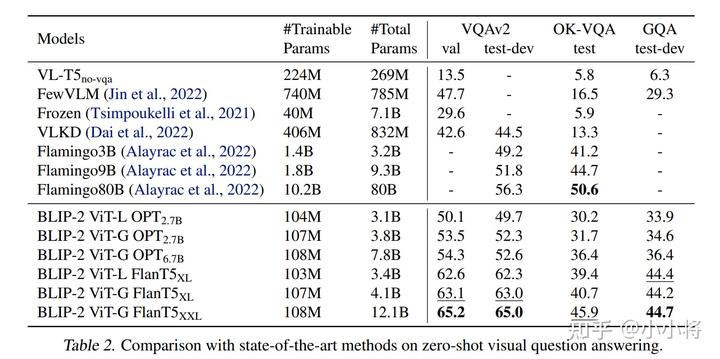
12.1B的BLIP-2之所以能夠比80B的Flamingo強(qiáng),我覺(jué)得最主要的原因還是在于視覺(jué)特征嵌入到LLM的方式,F(xiàn)lamingo引入了額外的cross-attention層來(lái)實(shí)現(xiàn)這種嵌入,反而有點(diǎn)破壞了原來(lái)的LLM,而B(niǎo)LIP-2這種直接將視覺(jué)特征轉(zhuǎn)到LLM特征空間就能夠很好的保持原有模型能力。
MiniGPT-4
MiniGPT-4是近期的工作,它其實(shí)可以看成是BLIP-2的升級(jí)版本。在ChatGPT發(fā)布之后,其實(shí)已經(jīng)有越來(lái)越多的開(kāi)源工作來(lái)復(fù)現(xiàn)ChatGPT的效果,目前很多工作是使用高質(zhì)量數(shù)據(jù)在Meta開(kāi)源的LLaMA進(jìn)行finetune。所以,MiniGPT-4直接選擇了一個(gè)效果更好的LLM:Vicuna,它是基于ShareGPT數(shù)據(jù)集finetune的模型,號(hào)稱用GPT-4來(lái)評(píng)測(cè)可以達(dá)到ChatGPT 90%的水平。它是基于LLaMA-13B進(jìn)行finetune的,所以又稱為Vicuna-13B。 MiniGPT-4的模型結(jié)構(gòu)非常簡(jiǎn)單,如下所示,這里是直接將BLIP-2的預(yù)訓(xùn)練好的Q-Former拿過(guò)來(lái),這里Image Encoder用的是最大的 EVA-CLIP ViT-G/14模型。這里增加了一個(gè)Linear Layer來(lái)將Q-Former提取的特征映射到Vicuna的特征空間,得到的 soft prompt 就可以直接嵌入到Vicuna模型中。
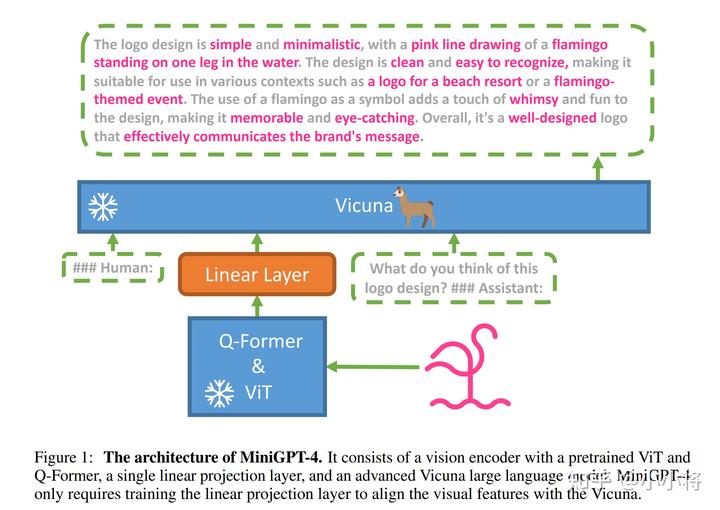
要注意的是,MiniGPT-4這里不僅凍結(jié)了Vicuna模型,而且凍結(jié)了Q-Former,所以訓(xùn)練參數(shù)只剩下一個(gè)Linear Layer了。那么重點(diǎn)就是MiniGPT-4是怎么訓(xùn)練的,或者說(shuō)MiniGPT-4采用了什么樣的數(shù)據(jù)來(lái)進(jìn)行訓(xùn)練。當(dāng)然,MiniGPT-4也可以簡(jiǎn)單地像BLIP-2那樣采用圖像文本對(duì)來(lái)訓(xùn)練,但是實(shí)驗(yàn)發(fā)現(xiàn)了這樣效果并不太好。 相比BLIP-2,MiniGPT-4采用了兩階段的訓(xùn)練策略,這個(gè)兩階段和BLIP-2不太一樣,其實(shí)BLIP-2的第一階段只是為了得到初步的Q-Former,并沒(méi)有涉及LLM。 MiniGPT-4的第一階段訓(xùn)練和BLIP-2的第二階段一樣,采用圖像文本對(duì)數(shù)據(jù)集進(jìn)行訓(xùn)練,訓(xùn)練目標(biāo)是基于soft prompt來(lái)生成對(duì)應(yīng)的文本描述,訓(xùn)練數(shù)據(jù)集是CC、SBU和LAION數(shù)據(jù)集中篩選的5M樣本。完成這個(gè)階段的訓(xùn)練后,雖然模型能夠有一定的生成能力,但是它比較難產(chǎn)生連貫的語(yǔ)言,比如生成重復(fù)的單詞或句子、零散的句子或不相關(guān)的內(nèi)容。論文任務(wù)模型需要 instruction fine-tuning或者RLHF,這也是GPT-3到GPT-3.5進(jìn)化的關(guān)鍵。 所以MiniGPT-4的第二階段構(gòu)建了一個(gè)高質(zhì)量的圖像文本數(shù)據(jù)集來(lái)進(jìn)行finetune。首先從CC數(shù)據(jù)集中選擇5000張圖像,然后使用第一階段訓(xùn)練好的模型來(lái)生成詳細(xì)的文本描述,這里采用了如下所示的prompt來(lái)進(jìn)行生成:
###Human: Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
但是這里生成的文本質(zhì)量可能存在噪音或者錯(cuò)誤,所以又基于ChatGPT來(lái)對(duì)生成的文本進(jìn)行refine,這里采用的prompt是:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation
另外為了保證數(shù)據(jù)質(zhì)量,最后還是人工對(duì)ChatGPT美化后的文本進(jìn)行檢查,最終選出了大約3500個(gè)樣本。然后基于這些樣本進(jìn)行第二階段finetune,這里首先將數(shù)據(jù)集按照如下prompt構(gòu)建:
###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:
這里的從一些預(yù)先定義好的模版中選取,比如“Describe this image in detail” 和 “Could you describe the contents of this image for me”。訓(xùn)練的優(yōu)化目標(biāo)就是根據(jù)prompt來(lái)生成對(duì)應(yīng)的文本。論文里面說(shuō)第二階段的finetune非常高效,在batch=12下只需要訓(xùn)練400 steps就可以了。 經(jīng)過(guò)第二階段finetune的MiniGPT-4的生成效果就有明顯改善,它不僅可以對(duì)圖像生成詳細(xì)的描述,也可以識(shí)別圖像中有趣的地方,甚至發(fā)現(xiàn)圖像中異常內(nèi)容,具體的示例如下所示:

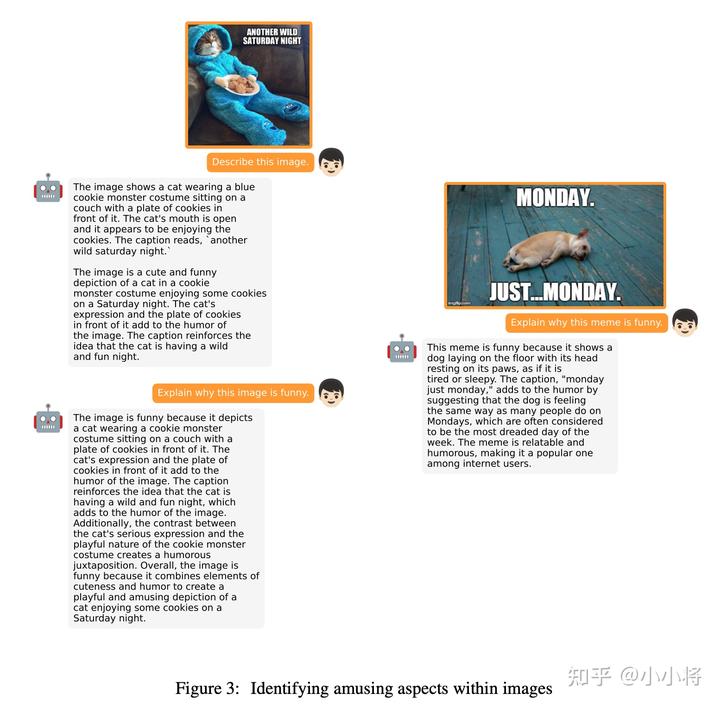

MiniGPT-4甚至可以像GPT-4一樣根據(jù)手寫(xiě)內(nèi)容生成網(wǎng)站代碼:
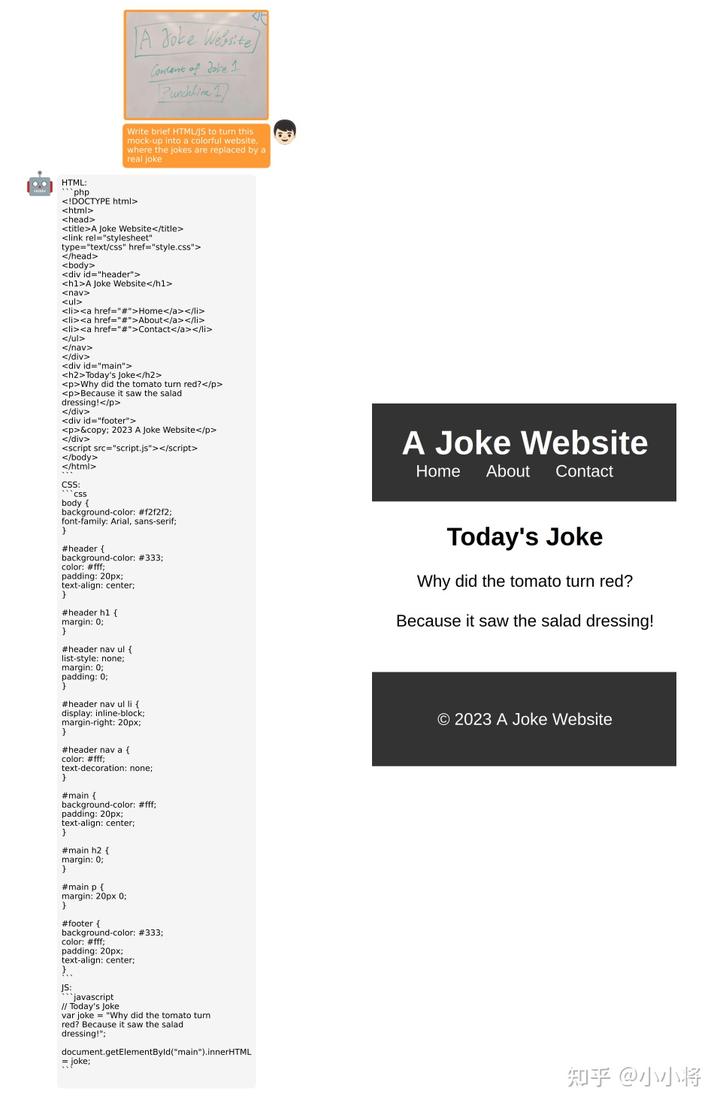
相比較BLIP-2來(lái)說(shuō),MiniGPT-4提升的關(guān)鍵在于采用了更好的LLM,同時(shí)采用了高質(zhì)量數(shù)據(jù)集進(jìn)行finetune。但論文中也說(shuō)到MiniGPT-4也存在一定的局限性,比如無(wú)法從圖像中獲取細(xì)粒度的信息以及無(wú)法識(shí)別位置信息,我想這主要還在于第二階段構(gòu)建的數(shù)據(jù)集的多樣性較少,另外只finetune了一個(gè)linear layer。
LLaVA
LLaVA(Large Language and Vision Assistant)是微軟最新的一個(gè)工作,這個(gè)工作的模型設(shè)計(jì)和MiniGPT-4基本一樣,但是更簡(jiǎn)單,如下所示:
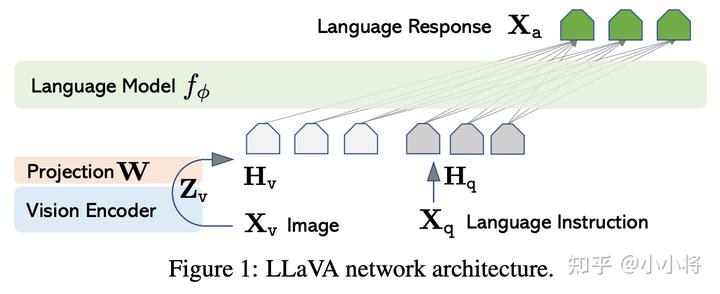
這里的Vision Encoder直接采用預(yù)訓(xùn)練好的CLIP ViT-L/14模型,然后直接用它倒數(shù)第二層的grid特征,加上一個(gè)Projection層映射到LLM的特征空間。相比BLIP-2和MiniGPT-4引入Q-Former,LLaVA可謂是簡(jiǎn)單粗暴。另外對(duì)于語(yǔ)言模型,LLaVA也采用了基于Meta的LLaMA進(jìn)行finetune的模型Vicuna。LLaVA最重要的部分是它如何構(gòu)建高質(zhì)量的multimodal instruction-following dataset,前面的工作基本上都是用圖像文本對(duì)數(shù)據(jù)集來(lái)進(jìn)行訓(xùn)練,這肯定是存在一定的局限性,但是目前又沒(méi)有更好的數(shù)據(jù)集,LLaVA給出的解決方案是采用GPT-4(或者ChatGPT)來(lái)生成這樣的數(shù)據(jù)集,注意這里并不是依賴GPT-4的多模態(tài)能力,而只用GPT-4的文本理解和生成能力。雖然我們不能給GPT-4真送入一張圖像,但是其實(shí)我們可以模擬這個(gè)場(chǎng)景,這里我們用一個(gè)非常詳盡的文本描述來(lái)替代圖像輸入。LLaVA使用兩種類型的文本描述:
- captions:從不同的角度描述圖像內(nèi)容;
- Bounding boxes:定位圖像中的物體,每個(gè)框編碼物體類別及其空間位置。
下面是一個(gè)具體的示例:

這兩方面的描述算是近似等價(jià)于圖像,送入GPT-4中就如同送入圖像本身。論文采用COCO中的圖像,共根據(jù)GPT-4產(chǎn)生3種類型的instruction-following data: 第一種是Conversation:構(gòu)建視覺(jué)問(wèn)答的多輪對(duì)話數(shù)據(jù),具體是通過(guò)如下的方式來(lái)生成:

第二種是Detailed description:根據(jù)圖像生成詳細(xì)的描述,這里采用如下的prompt來(lái)讓GPT-4生成:

第三種是Complex reasoning:前面的兩種主要是和圖像內(nèi)容有關(guān),這部分是構(gòu)建復(fù)雜的推理問(wèn)題,這里需要手工設(shè)計(jì)一些問(wèn)題來(lái)讓GPT-4來(lái)生成。 論文中共構(gòu)建了158K樣本,其中 conversations 有58K,detailed description有23K,complex reasoning有77K。下面是根據(jù)前面的圖像示例來(lái)構(gòu)建的三種類型數(shù)據(jù)的示例:

相比較MiniGPT-4,LLaVA構(gòu)建的instruction-following data多樣性更好,這也能讓模型學(xué)習(xí)到更強(qiáng)的視覺(jué)理解能力。 具體在訓(xùn)練方面,LLaVA也采用了兩階段的訓(xùn)練策略。第一階段采用CC3M中篩選的595K圖像文本對(duì)訓(xùn)練,這里采用的任務(wù)是根據(jù)圖像來(lái)生成對(duì)應(yīng)的文本描述,其中prompt采用如下的方式:

注意第一階段Vision Encoder和LLM都是凍結(jié)的,只finetune了Projection層,所以第一階段主要是讓圖像特征能夠映射到LLM的特征空間。 第二階段采用收集的instruction-following data數(shù)據(jù)集來(lái)進(jìn)行finetune,這個(gè)階段Vision Encoder是凍結(jié)的,同時(shí)訓(xùn)練LLM和Projection層。具體訓(xùn)練樣式如下所示:

下面是LLaVA的幾個(gè)具體示例,可以看到它比BLIP-2和OpenFlamingo有更強(qiáng)的視覺(jué)理解能力:


這里也放一個(gè)LLaVA讓人驚艷的例子,它不僅能識(shí)別藝術(shù)作品,而且給定仿造品也能識(shí)別:

總結(jié)
這里我們簡(jiǎn)單總結(jié)了和GPT-4多模態(tài)能力相關(guān)的四個(gè)工作,再回到我們開(kāi)頭的總結(jié),可以看到這四個(gè)工作都選擇了具有多模態(tài)能力的CLIP模型來(lái)提取圖像特征,而將圖像特征連接到語(yǔ)言模型的方式略有不同,后面的工作很重要的方面是構(gòu)建高質(zhì)量的圖文多模態(tài)數(shù)據(jù)集。所以雖然GPT-4并沒(méi)有開(kāi)源,但是可以想象,GPT-4也應(yīng)該是采用了一個(gè)多模態(tài)的視覺(jué)模型,很有可能是CLIP,另外GPT-4應(yīng)該構(gòu)建了一個(gè)比較好的圖文數(shù)據(jù)集來(lái)進(jìn)行訓(xùn)練。
參考
- https://openai.com/research/gpt-4
- GPT-4 Technical Report
- https://github.com/Vision-CAIR/MiniGPT-4
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- Visual Instruction Tuning
- https://arxiv.org/abs/2304.10592
上一篇:4-4






