K8s調度器Scheduler
當創建k8s pod的時候調度器會決定pod在哪個node上被創建且運行,調度器給apiserver發出了一個創建pod的api請求,apiserver首先將pod
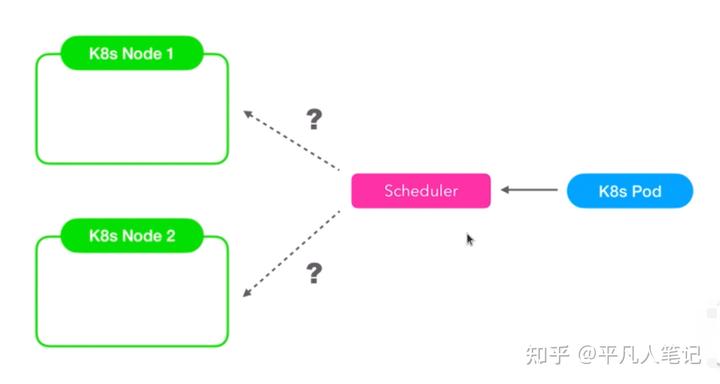
當創建k8s pod的時候調度器會決定pod在哪個node上被創建且運行,
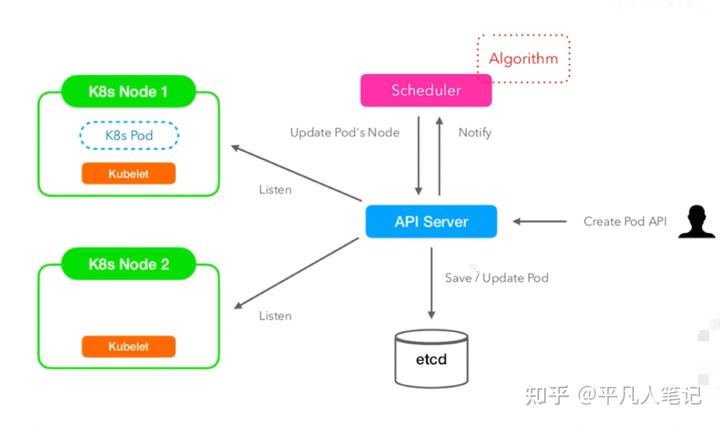
調度器給apiserver發出了一個創建pod的api請求,apiserver首先將pod的基本信息保存在etcd,apiserver又會把這些信息給到每個node上的kubelet進程,kubelet一直在監聽這些信息,當kubelet發現這個pod的節點信息跟它當前運行的節點一致的時候,就會創建pod進程以及容器當中的docker image進程,創建相應的命名空間,使得進程之間互相隔離,這樣pod就在這個節點上運行起來了。
k8s調度器會盡量的去保證所有節點上的資源是相對平衡的,判斷節點資源(CPU、內存、存儲、端口等)是否適合Pod的資源申請。
查看K8s資源在etcd中的信息
借助kube-etcd-helper這個工具查看etcd中的內容,
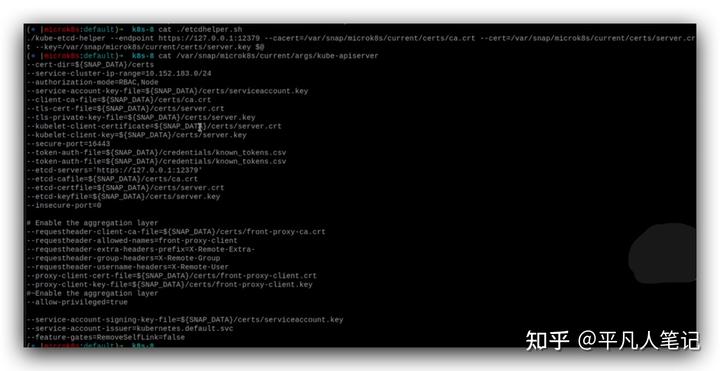
寫一個操作etcd命令的腳本./etcdheloper.sh,指定etcd的地址,鑒權需要的證書等信息,
查看k8s資源列表,./etcdheloper.sh ls
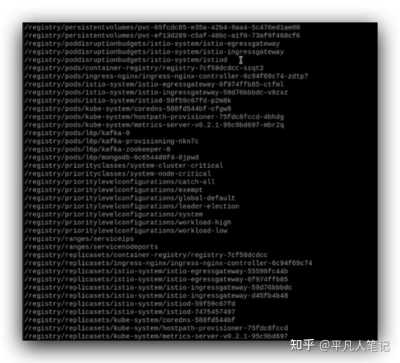
這是etcd中保存的k8s資源信息,查看指定的pod信息,
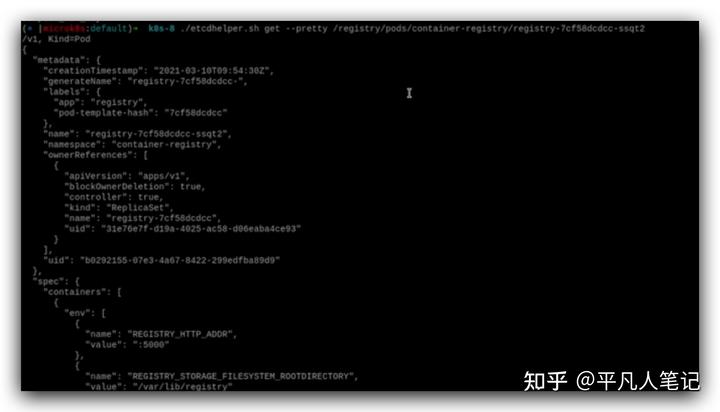
跟調度器相關的是這個nodeName,
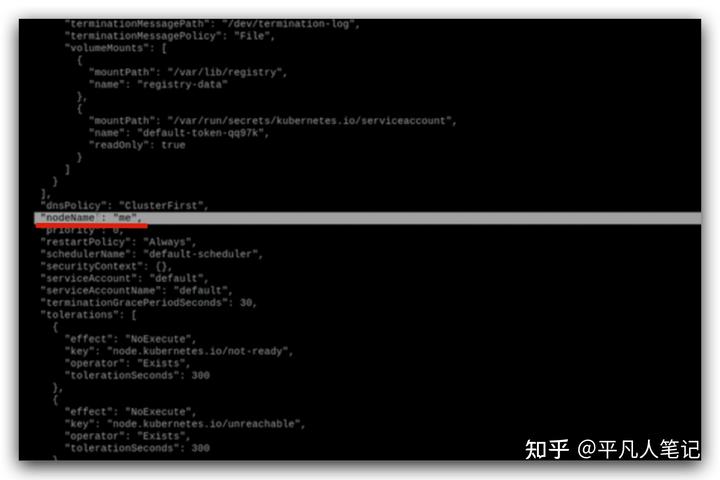

驗證調度器的工作方式
有了etcd helper可以更加詳細的看下調度器的工作原理,調度器一直在監聽k8s中的pod的創建,通過etcd watch的功能可以去監聽一個pod的創建并且看到創建的整個過程。

創建這個pod,使用etcd helper來監聽下這個pod在etcd當中變動的過程,

通過這個命令可以看到在etcd中關于這個pod產生了4次變動,每次變動都是一個json,通過JSON Diff工具比較每次json都變動了哪些內容,
第一個json和第二個json比較,多了一個nodeName,

第一次給apiserver發送請求把這個信息保存在etcd當中的時候還沒有nodeName,第二次就是更新nodeName,調度器通過算法決定了這個pod要在這個node上創建,

這里聲明了pod已經被調度了;
第三次的json相比第二次json的變更內容:

記錄了pod中container容器的啟動狀態和pod的ip。
Pod指定節點運行

這是集群中node的情況,
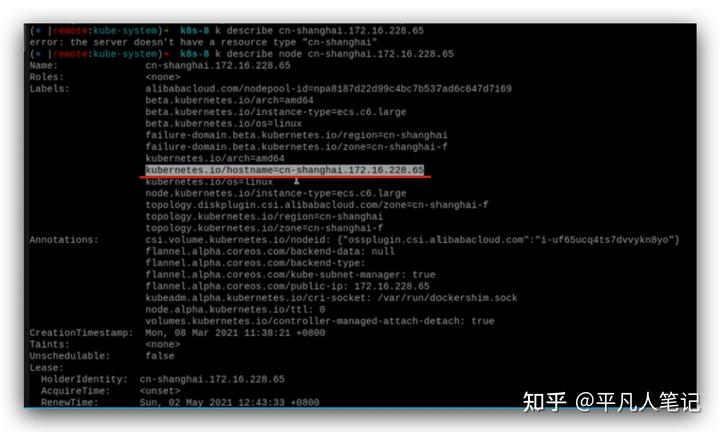
查看指定node的詳情,紅色部分決定了node的名稱,
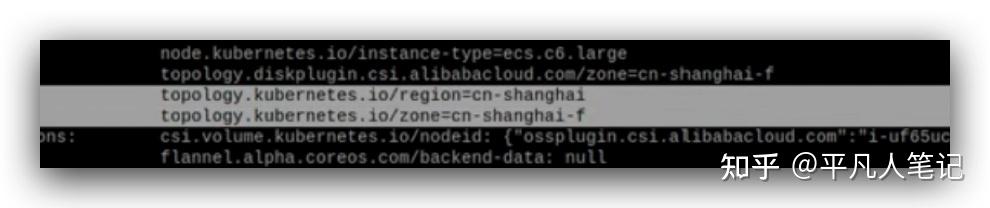
這個分別代表節點所在的區域和時區,

每個地域完全獨立,但同一個地域的可用區中間是互通的。
地域是指電力和網絡互相獨立的區域;同一可用區內實例之間的網絡延遲更小;
關鍵點是電力和網絡相互獨立,這個是在災備的時候要考慮的。
數據庫、k8s的節點、消息隊列等常用的資源都是需要做冗余的,如果在一個可用區內做大量的冗余,
看起來比較安全,一旦這個可用區廢掉了,所有的冗余信息在短時間內是不可工作的,跨可用區做冗余可用性就會得到極大的增強。
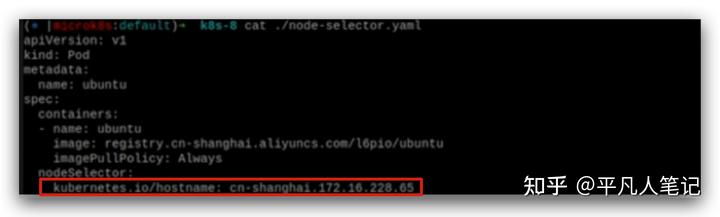

pod在指定的node上運行。
正常工作的節點

這是正常工作的節點,pod通過kubelet這個進程被創建出來。
kubectl向apiserver發送了一個請求,apiserver就把請求信息存儲在etcd數據庫里,調度器通過事件的監聽,通過調度算法來決定pod將會被調度到哪個節點上去,確定是哪個node之后,所以就在etcd的pod信息里面增加了一個nodeName。
kubelet也進行監聽,當它發現調度器分配這個pod到某一個節點信息修改的時候,來看這個節點是不是屬于它當前運行的node,如果是的話,就會創建這個pod。
k8s是go語言寫的,一般用glog打日志,
k8s 基于glog fork出來一個klog,k8s內核是用klog來記錄日志的。

glog有個參數:-v,表示日志的詳細程度,

從日志中可以看到,在創建pod的時候,先判斷pod是否存在,如果不存在的話,則創建。
有2種情況不屬于正常工作的節點,

pod不能被調度到節點或者pod根本不可以在節點上運行,比如這個節點的systemd后臺進程有問題導致節點不能正常運行,并不代表節點所在的虛擬機崩潰了,但是作為k8s節點是不能正常運行的,這種情況下node被打上一個污點。
NoScheduler表示不能調度到指定節點上;
NoExecute表示新的pod將不可以被調度到指定node上運行,當前在上面運行的pod也將被驅逐。
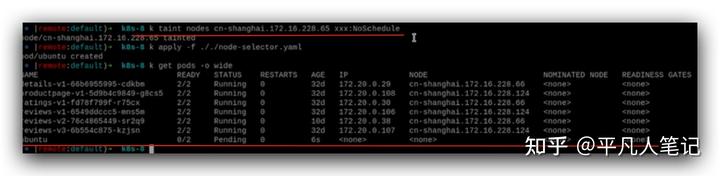
參數名稱可以任意起,污點一旦被創建,對節點就生效了,ubuntu這個pod狀態一直pending,就表示調度不過去 ,原因就是因為這個node被打上了污點。
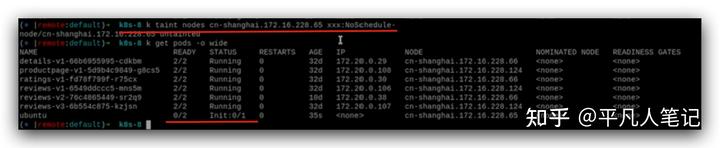
解除污點,pod就被調度到這個node節點上啟動了。

給node打上NoExecute污點,

這個節點上面的這個pod直接就停掉了,

去掉NoExecute污點,新的pod就可以在這個節點上運行了。
給node打污點的情況實際用的比較少,除非排錯,比如pod還能在node上跑,不希望新的pod被調度過來,先打一個污點,再在上面排查問題。
如果要重啟node或修改配置,一般通過拉警戒線的方式,

跟打污點的效果是一樣的,
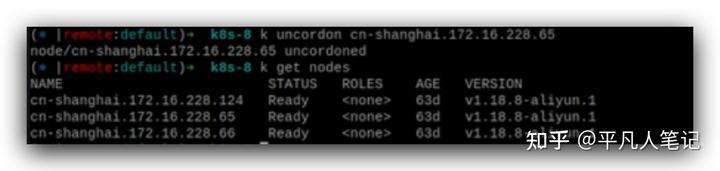
去除警戒線。
打污點或拉警戒線的使用場景:
場景1,比如阿里云systemd進程因版本的問題需要升級,會用這個命令,
場景2,節點有特殊的工作用途,比如master節點,一般至少用2個node做master節點,阿里云可以去托管master節點,比如當前的集群中只有worker節點沒有master節點是因為被阿里云托管了,對于這種情況也需要給master node打上污點,不將pod調度到master node上去。
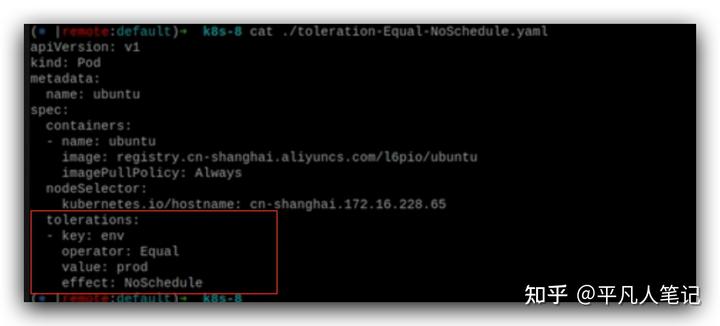
打污點key有兩種形式,一種是以字符串label的方式,

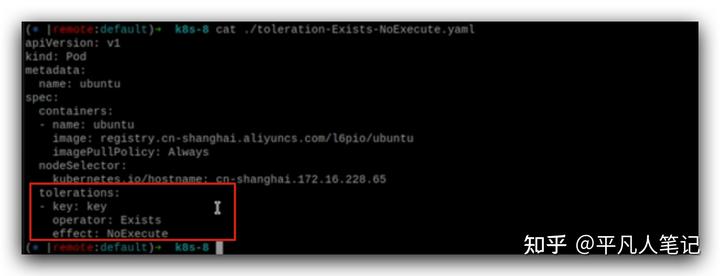
另外一種比如env=prod,

表示節點是測試環境還是生產環境。
除非pod有env=prod并且可以容忍NoExecute這樣的標簽,才能被調度在這個pod上,
node親和性
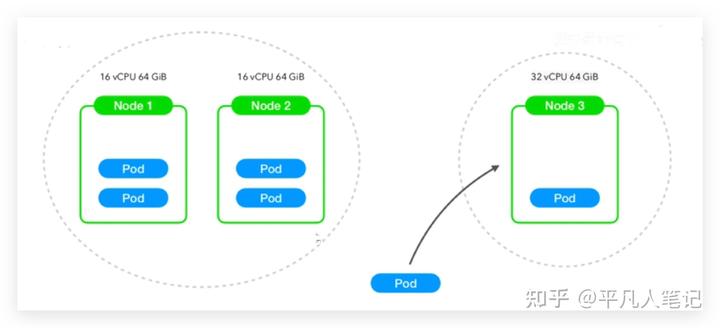
node1 16核64G內存,node2 16核64G內存,node3 32核 64G內存,讓pod向性能比較好的node上運行即pod親和node3,
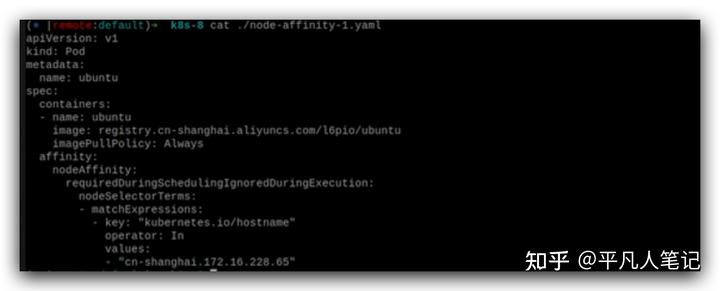
pod親和于什么樣的node去運行,在調度的時候affinity是必須的,但在實際運行的時候又用不到,只是調度的時候用到。
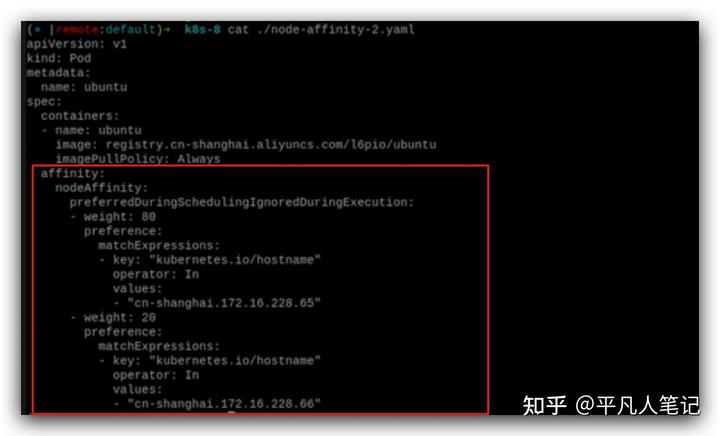
在調度的時候80%的概率到一個node,20%的概率到另外一個node。
pod的親和性
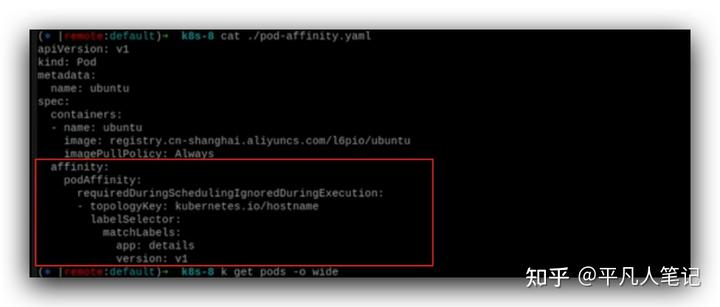
details pod運行在哪個node上,ubuntu pod也運行在details pod所在的node上,
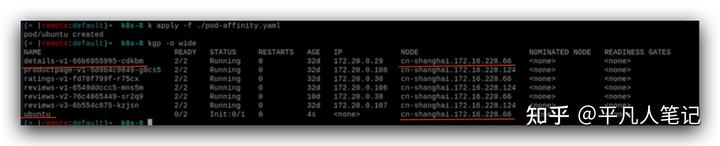
實際運用的場景比如前后端的pod運行在同一個node上。啟動pod的時候去查有沒有滿足app:details這個條件的pod,如果有的話,就在運行在這個pod所在的node上。
pod的反親和性
每個node有不同的hostname,如果發現這個node上已經運行了跟我一樣label的pod,那我就不在這個node上運行了,再找一個新的node即同樣的一個pod不在同一個node上運行這樣的效果,
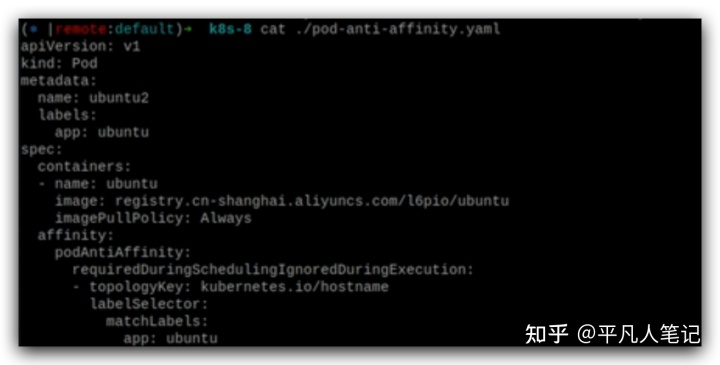

65這個node上已經運行了ubuntu了,
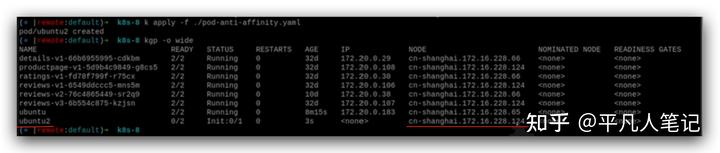
再啟動一個ubuntu,就不會在65這個node上運行了,而是在124這個node上運行,

再運行ubuntu3和ubuntu4,為什么ubuntu4一直pending是因為每個node上都有ubuntu了,4沒有node可以運行了。
pod親和度使用場景比較多,node親和度幾乎用不到,因為同一個集群,盡量使用同樣的ecs虛擬機,盡量不要有差異化。
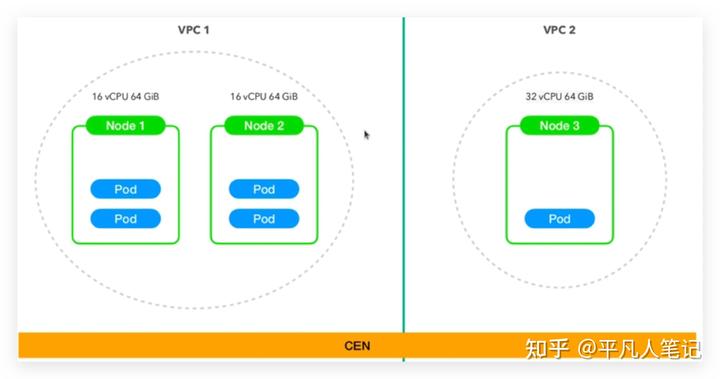
就算要區分環境,比如這2臺配置比較小的機器做測試環境,(生產環境的機器要比測試環境多的多,這里只是做假設),更傾向于配成2個不同的vpc(私有云)
,每個vpc有自己獨立的網段,2個vpc相對安全些,讓2個網段互通可以使用阿里云的cen,

這樣比較好,而不是做一個大的集群(里面什么樣的node都有),再通過打污點、打標簽,個人感覺這樣會比較累。
,
上一篇:k8s三節點部署文檔
下一篇:MSDS與SDS的區別和相同點








