工業蒸汽量預測比賽全流程解析(附詳細Python代碼)
采用的數據集情況本文所采用的數據集來自于阿里云天池比賽,比賽的鏈接地址為:阿里云天池工業蒸汽量預測比賽鏈接其中所下載的數據集
采用的數據集情況
本文所采用的數據集來自于阿里云天池比賽,比賽的鏈接地址為:阿里云天池工業蒸汽量預測比賽鏈接
其中所下載的數據集包括兩個txt文件:zhengqi_train.txt(訓練集)和zhengqi_test.txt(測試集)
數據導入
因本文的主要目的是以介紹整個挖掘流程為主,因此采用根據需要逐步導入所需要的庫的形式,以下先導入numpy和pandas兩個庫。
import numpy as npnimport pandas as pd
使用pandas導入已經預先下載并存放在本地的訓練集和測試集,結合本次的數據集為txt文件,并且數據之間的分隔符為't',因此導入文件的代碼如下:
df_train=pd.read_csv(r'D:zhengqizhengqi_train.txt',sep='t')ndf_test=pd.read_csv(r'D:zhengqizhengqi_test.txt',sep='t')
數據概覽
使用head查看訓練集和測試集前5條數據的情況
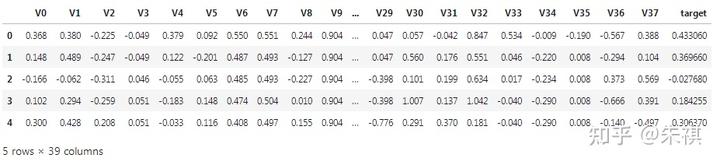
df_train.head()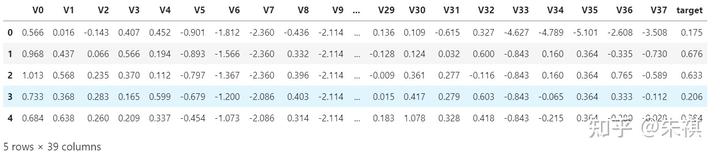
從圖中可以看到,訓練集總共有39列,其中包括V0至V37共38個特征,target為本次的預測標簽值。
df_test.head()
測試集總共有38列,其中包括V0至V37共38個特征,沒有target,本次的預測就是需要根據訓練完成的模型,提交測試集的target值。
使用info查看訓練集和測試集的整體情況如下:
df_train.info()

可以看到,訓練集的數據總數為2888條,因為Python默認的index排序是從0開始,所以index顯示為0至2887條。non-null代表數據中沒有缺失值,因此不需要對于數據進行缺失值填充;float64(39)代表39列數據全部為浮點形式數值數據,不需要進行格式上的轉換。
df_test.info()
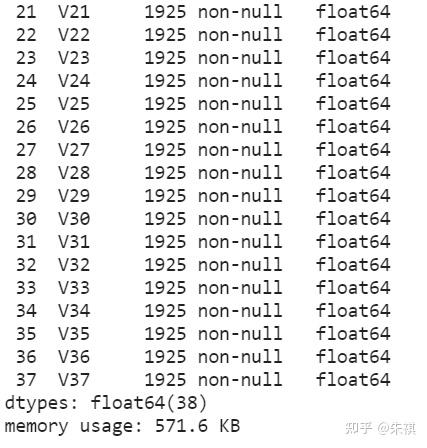
測試集的數據總數為1925條,index序號為0至1924條。測試集中的數據同樣沒有缺失值;float64(38)代表38列數據全部為浮點形式數值數據,不需要進行格式上的轉換。因此,訓練集數據的總體情況和測試集數據是一致的。
特征工程
加載接下去要使用的兩個庫,matplotlib和seaborn都是Python中常用的可視化工具庫。
import matplotlib.pyplot as pltnimport seaborn as sns
用以下代碼提取出訓練集中所有的特征標簽,方便之后使用:
#提取df_train中的特征標簽,并將起轉換成列表形式nfeature_list=list(df_train.columns)n#為方便之后使用,去掉列表中被一并提取出來的target標簽,確保僅留特征標簽nfeature_list.remove('target')n#顯示特征標簽列表nfeature_list
feature_list即特征標簽列表如下:
['V0','V1','V2','V3','V4','V5','V6','V7','V8','V9','V10','V11','V12','V13','V14','V15','V16','V17', 'V18', 'V19', 'V20', 'V21', 'V22', 'V23', 'V24','V25', 'V26', 'V27', 'V28', 'V29', 'V30', 'V31',
'V32', 'V33', 'V34', 'V35', 'V36', 'V37']
數據分布情況核實
首先需要核實的是訓練集的各特征數據分布情況是否和測試集一致,當兩者出現較大差異時,將會導致模型失效的情況,可視化對比過程如以下代碼所示:
#對于特征標簽列表feature_list中的特征標簽進行操作,逐個繪制單變量數據n分布圖,訓練集和測試集的相同特征分布情況繪制在同一張圖上以方便比對nfor i in feature_list:n sns.distplot(df_train[{i}])n sns.distplot(df_test[{i}])n plt.title(i)n plt.show()
對于特征數較多的數據集,采用subplot方式繪制各類圖是更好的選擇,本文因為特征數并不算太多,為了更清晰的進行可視化展現,采用了一個for循環進行逐幅繪制的方式。
從V0到V37,總共生成了38幅單變量數據分布圖,其中藍色的是某特征訓練集的數據分布情況,黃色的是測試集的數據分布情況。根據這38幅圖,可以判斷訓練集和測試集各個特征的數據分布是否一致。以下選取典型的4幅作說明:
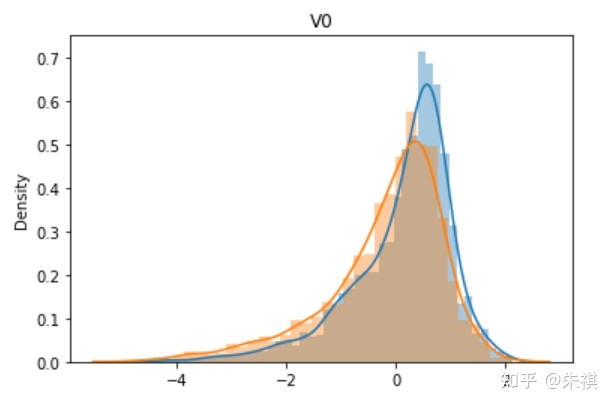
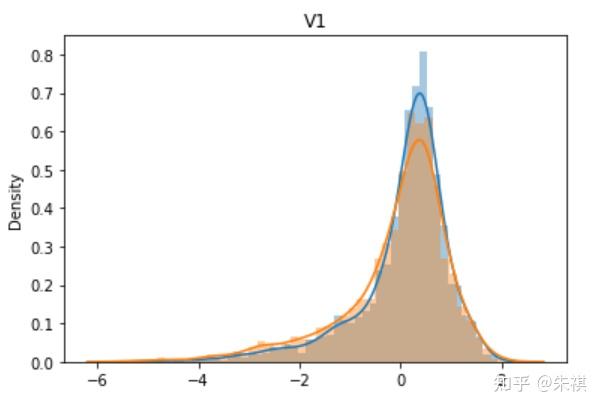
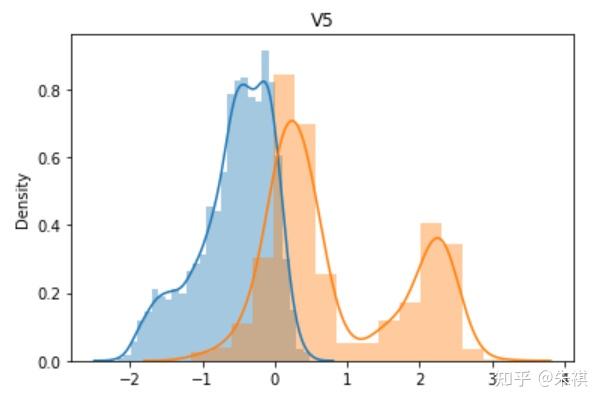
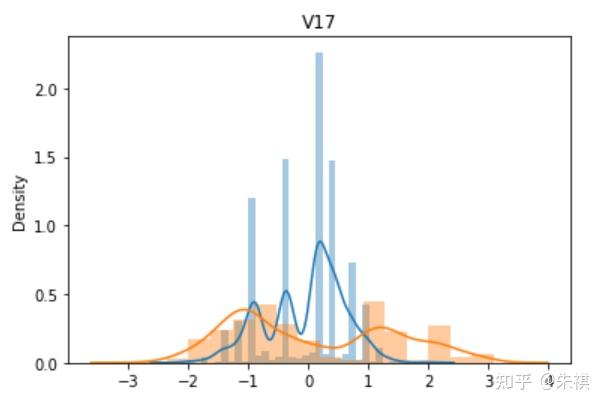
理想狀態下,針對同一特征,訓練集的數據分布曲線應該和測試集的數據分布曲線完全一致,但是這在實際過程中并不多見。如V0和V1兩個特征的分布圖可以發現,雖然訓練集和測試集的數據分布情況略有差異,但仍然可以認為是分布情況一致的。而V5和V17特征圖清晰的反映了數據分布不一致的情況。
同時在訓練集和測試集中將數據分布不一致的特征去除,代碼如下:
df_train=df_train[['V0','V1','V3','V4','V8','V10','V12','V15','V16','V18','V24','V25','V26','V28','V29','V30','V31','V32','V33','V34','V36','target']]ndf_test=df_test[['V0','V1','V3','V4','V8','V10','V12','V15','V16','V18','V24','V25','V26','V28','V29','V30','V31','V32','V33','V34','V36']]
因為訓練集和測試集的特征經過了篩選都發生了變化,為了方便之后的操作,重新提取出訓練集中所有的特征標簽,更新特征標簽列表feature_list:
#提取df_train中的特征標簽,并將起轉換成列表形式nfeature_list=list(df_train.columns)n#為方便之后使用,去掉列表中被一并提取出來的target標簽,確保僅留特征標簽nfeature_list.remove('target')n#顯示特征標簽列表nfeature_list
更新后的特征標簽列表feature_list如下:
['V0','V1','V3','V4','V8','V10','V12','V15','V16','V18','V24','V25','V26','V28','V29','V30','V31','V32','V33','V34','V36']
相關性分析
對于訓練集進行相關性分析,所采用的方法為計算皮爾遜相關系數,Python中可以直接在數據集上采用corr的方法,默認的相關系數計算方式就是皮爾遜相關系數。
df_train.corr()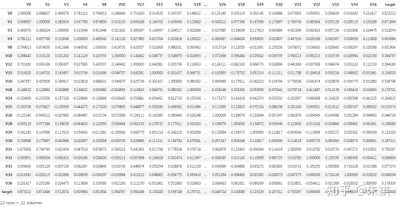
本文的案例我們只分析各特征標簽與預測標簽(target)之間的相關性,查看上表的最后一列相關系數計算結果,相關系數的絕對值大于0.5的為強相關性,小于0.5的為弱相關性,0附近的為沒有相關性,系數為正代表正相關,系數為負代表負相關。
以可視化方法繪制特征標簽與預測標簽(target)的散點圖,與相關系數的計算結果進行相互校對:
for i in feture_list:n sns.scatterplot(df_train[f'{i}'],df_train['target'])n plt.show()
在生成的所有散點圖中挑選幾幅典型的圖來說明不同的相關系數下,散點圖的大致形狀:
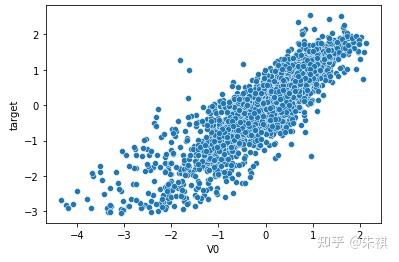
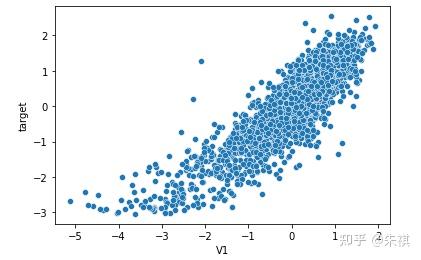
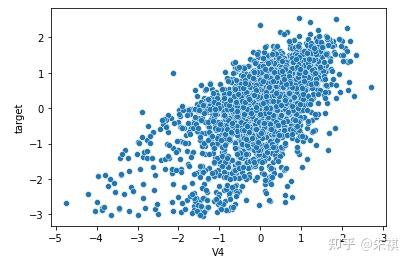
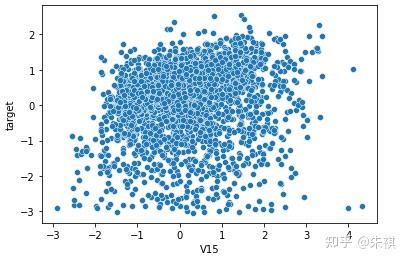
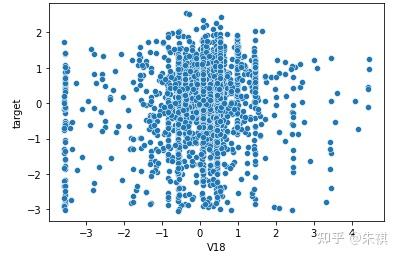
以0.5為界限,同時在訓練集和測試集中去除相關系數絕對值低于0.5的特征,確保被輸入模型進行訓練的特征與預測目標值有較強的相關性。
df_train=df_train[['V0','V1','V3','V4','V8','V12','V16','V31','target']]ndf_test=df_test[['V0','V1','V3','V4','V8','V12','V16','V31']]
因訓練集和測試集的特征再次經過篩選,因此再次更新特征標簽列表feature_list:
#提取df_train中的特征標簽,并將起轉換成列表形式nfeature_list=list(df_train.columns)n#為方便之后使用,去掉列表中被一并提取出來的target標簽,確保僅留特征標簽nfeature_list.remove('target')n#顯示特征標簽列表nfeature_list
更新后的特征標簽列表feature_list如下:
['V0','V1','V3','V4','V8','V12','V16','V31']
正態分布檢驗
對于完成進一步篩選的數據集做正態分布檢驗,以確定是否需要進一步將數據盡可能轉換成正態分布的形式,本文同樣同時采用指標計算的方法和可視化的方法來同時進行正態分布檢驗。
導入正態分布檢驗所需要用到的庫:
from scipy import stats
首先檢驗各個特征中數據的偏度,偏度定義中包括正態分布(偏度=0),右偏分布(也叫正偏分布,其偏度>0),左偏分布(也叫負偏分布,其偏度<0)。
for i in feture_list:n skew = stats.skew(df_train[f'{i}'])n print(f'the skew value of feture {i} is {skew}')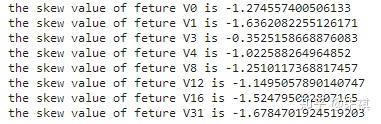
根據偏度的檢驗結果,各個特征的數據都為左偏,但是總體都滿足正態分布。之后檢驗各個特征中數據的峰度。若峰度≈0,分布的峰態服從正態分布;若峰度>0,分布的峰態陡峭(高尖);若峰度<0,分布的峰態平緩(矮胖)。
for i in feture_list:n kurtosis = stats.kurtosis(df_train[f'{i}'])n print(f'the kurtosis value of feture {i} is {kurtosis}')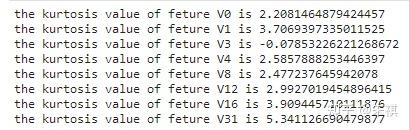
根據偏度的檢驗結果,各特征的數據總體都滿足正態分布。采用可視化的方法對于指標的計算結果進行確認,結果如下:
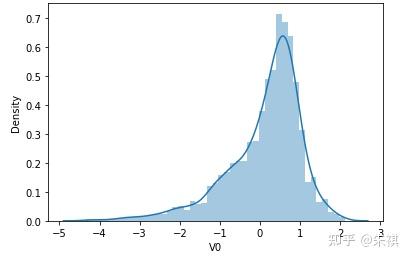
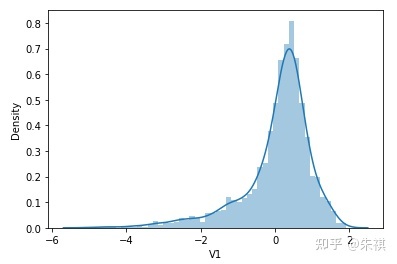
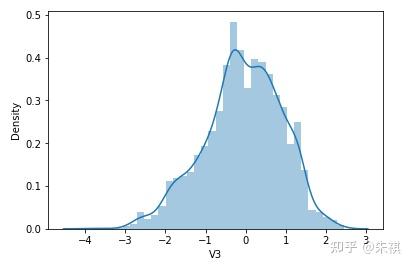
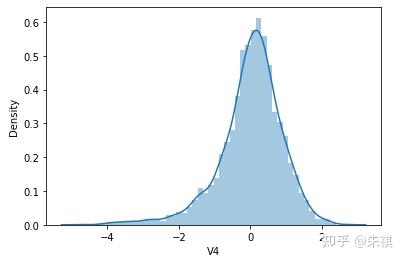
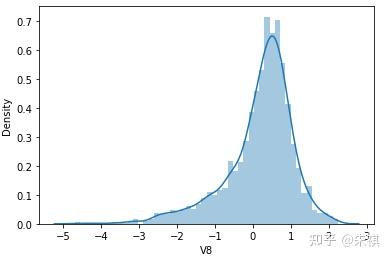
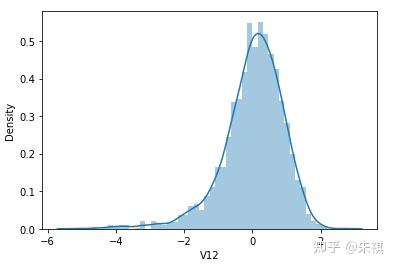
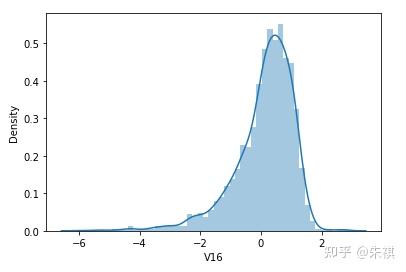
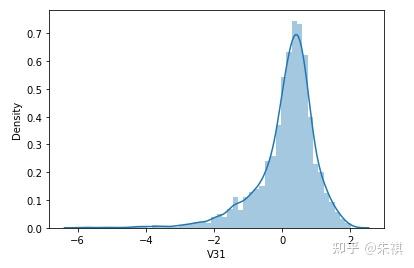
可視化的檢驗結果與指標檢驗結果一致,因此正態分布檢驗的結論為:各特征數據基本符合正態分布,本文后續不對數據進行正態分布轉換處理。
數據集拆分
因為本文的數據來自比賽,因此測試集單獨提供,測試集的預測結果作為比賽的評定指標。對于訓練集進一步拆分出交叉驗證集以判斷模型的預測效果,同時確保交叉驗證集的數據與訓練集數據完全獨立:
from sklearn.model_selection import train_test_splitndf_train_value, df_vali_value, df_train_target, df_vali_target=train_test_split(df_train_value, df_train_target, test_size=0.25,random_state=1)
拆分完的數據集如下所示:
df_train_value:訓練集特征數據集(總數據的75%)
df_train_target:訓練集的預測目標數據(總數據的75%)
df_vali_value:交叉驗證集特征數據集(總數據的25%)
df_vali_target:交叉驗證集的預測目標數據(總數據的25%)
模型訓練及檢驗
對于df_train_value,df_train_target,df_vali_value,df_vali_target的index進行重置,確保所有數據都從第0條開始排序:
df_train_value=df_train_value.reset_index(drop=True)ndf_vali_value=df_vali_value.reset_index(drop=True)ndf_train_target=df_train_target.reset_index(drop=True)ndf_vali_target=df_vali_target.reset_index(drop=True)
對重置完成的各個數據集,將數據轉換成矩陣形式供后續使用:
df_train_value=np.array(df_train_value)ndf_vali_value=np.array(df_vali_value)ndf_train_target=np.array(df_train_target)ndf_vali_target=np.array(df_vali_target)
加載驗證指標MSE:
from sklearn.metrics import mean_squared_error
算法1:XGBoost
建立模型并進行訓練:
import xgboost as xgbnmodel_xgb=xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=160, silent=True, objective='reg:linear')nmodel_xgb.fit(df_train_value,df_train_target)
對于交叉驗證集特征數據集df_vali_value進行預測:
predict_xgb=model_xgb.predict(df_vali_value)
將預測結果及交叉驗證集的預測目標數據對比進行指標驗證:
mean_squared_error(df_vali_target,predict_xgb)
在未進行深度調參的情況下,采用XGBoost進行預測得出的MSE為0.128。在此基礎上抽取交叉驗證集的100組數據采用可視化手段直觀檢驗預測效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_xgb[0:101])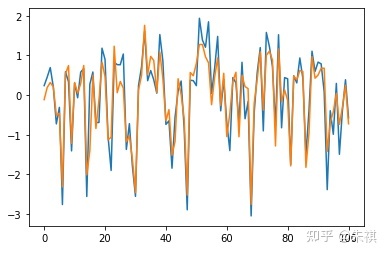
算法2:GBDT Regression
建立模型并進行訓練
from sklearn.ensemble import GradientBoostingRegressornmodel_gbdt=GradientBoostingRegressor(n loss='ls'n, learning_rate=0.03n, n_estimators=500n, subsample=1n, min_samples_split=2n, min_samples_leaf=1n, max_depth=3n, init=Nonen, random_state=Nonen, max_features=Nonen, alpha=0.9n, verbose=0n, max_leaf_nodes=Nonen, warm_start=Falsen)nmodel_gbdt.fit(df_train_value,df_train_target)
對于交叉驗證集特征數據集df_vali_value進行預測:
predict_gbdt=model_gbdt.predict(df_vali_value)
將預測結果及交叉驗證集的預測目標數據對比進行指標驗證:
mean_squared_error(df_vali_target,predict_gbdt)
在未進行深度調參的情況下,采用GBDT進行預測得出的MSE為0.13。在此基礎上抽取交叉驗證集的100組數據采用可視化手段直觀檢驗預測效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_gbdt[0:101])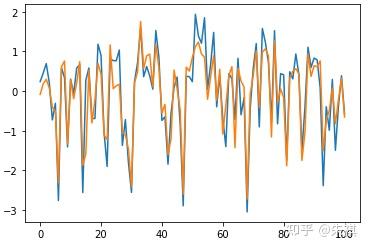
算法3:Random Forests
建立模型并進行訓練:
from sklearn.ensemble import RandomForestRegressornmodel_RF=RandomForestRegressor(n_estimators=200, random_state=0)
對于交叉驗證集特征數據集df_vali_value進行預測:
predict_RF=model_RF.predict(df_vali_value)
將預測結果及交叉驗證集的預測目標數據對比進行指標驗證:
mean_squared_error(df_vali_target,predict_RF)
在未進行深度調參的情況下,采用Random Forests進行預測得出的MSE為0.123。在此基礎上抽取交叉驗證集的100組數據采用可視化手段直觀檢驗預測效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_RF[0:101])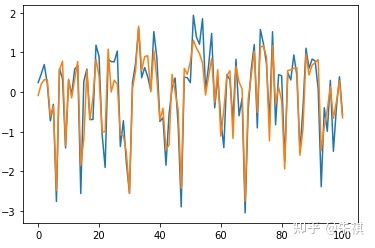
算法4:Bayesian Linear Regression
建立模型并進行訓練:
from sklearn import linear_modelnmodel_BR=linear_model.BayesianRidge()nmodel_BR.fit(df_train_value,df_train_target)
對于交叉驗證集特征數據集df_vali_value進行預測:
predict_BR=model_BR.predict(df_vali_value)
將預測結果及交叉驗證集的預測目標數據對比進行指標驗證:
mean_squared_error(df_vali_target,predict_BR)
采用Bayesian Linear Regression進行預測得出的MSE為0.125。在此基礎上抽取交叉驗證集的100組數據采用可視化手段直觀檢驗預測效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_BR[0:101])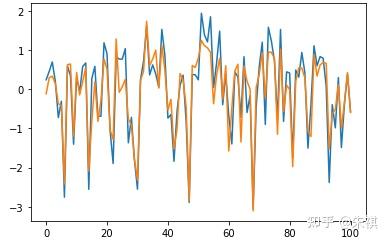
算法5:Linear Regression
建立模型并進行訓練:
from sklearn.linear_model import LinearRegressionnmodel_LR=LinearRegression()nmodel_LR.fit(df_train_value,df_train_target)
對于交叉驗證集特征數據集df_vali_value進行預測:
predict_LR=model_LR.predict(df_vali_value)
將預測結果及交叉驗證集的預測目標數據對比進行指標驗證:
mean_squared_error(df_vali_target,predict_LR)
采用Linear Regression進行預測得出的MSE為0.125。在此基礎上抽取交叉驗證集的100組數據采用可視化手段直觀檢驗預測效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_LR[0:101])
測試集預測
檢測測試集狀態是否正常:
df_test.head()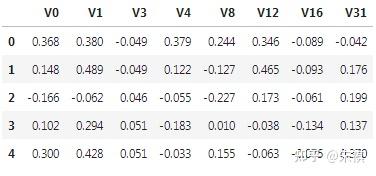
df_test.info()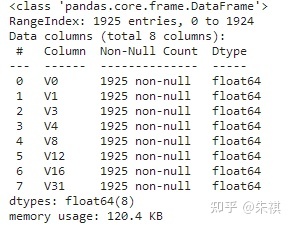
將測試集轉換為矩陣形式:
df_test=np.array(df_test)
采用MSE指標最低的模型進行預測,這里采用Random Forests算法模型:
predict_test=model_RF.predict(df_test)
制作提交文件完成實驗
按提交要求將預測結果predict_test作為新的一列插入測試集zhengqi_test.txt,標簽為target:
test_submit=pd.read_csv(r'D:天池工業蒸汽量預測zhengqi_test.txt',sep='t')ntest_submit['target']=predict_test
通過頭五組數據查看提交文件的狀態:
test_submit.head()