10 聚類
聚類 (Clustering)以下內(nèi)容基于周志華老師的機(jī)器學(xué)習(xí)第9章歸納整理。1 聚類任務(wù)無監(jiān)督學(xué)習(xí)(Unsupervised Learning)就是在樣本標(biāo)
聚類 (Clustering)
以下內(nèi)容基于周志華老師的機(jī)器學(xué)習(xí)第9章歸納整理。
1 聚類任務(wù)
無監(jiān)督學(xué)習(xí)(Unsupervised Learning)就是在樣本標(biāo)簽未知時(shí),研究數(shù)據(jù)內(nèi)在性質(zhì)及規(guī)律的學(xué)習(xí)。其中應(yīng)用最多的是聚類(clustering)。
2 性能度量
與監(jiān)督學(xué)習(xí)相同,我們需要通過某種性能度量來評(píng)估聚類結(jié)果好壞。直觀的講,我們希望物以類聚。就是同一簇盡可能相似,不同簇盡可能不同。 也就是說,簇內(nèi)相似度(intra-cluster similarity)高且簇間相似度(inter-cluster similarity)低。
聚類的性能度量大致有兩類。
一類是將結(jié)果與某個(gè)參考模型比較,稱為外部指標(biāo)(external index) - Jaccard系數(shù)(Jaccard Coefficient, JC) - FM指數(shù)(Fowlkes and Mallows Index, FMI) - Rand指數(shù)(Rand Index, RI)
上述度量結(jié)果均在[0,1]之間,越大越好。
另一類是不利用任何參考模型,稱為內(nèi)部指標(biāo)(internal index) - DB指數(shù)(Davies-Bouldin Index, DBI) - Dunn指數(shù)(Dunn Index,簡稱DI)
DBI越小越好,而DI則越大越好。
此處不再復(fù)寫書上的內(nèi)容,因?yàn)楦鶕?jù)筆者在文本方面的實(shí)戰(zhàn)經(jīng)驗(yàn),大多數(shù)指標(biāo)僅僅是理論可行。 首先,海量短文本聚類,沒有標(biāo)簽。標(biāo)注也不可能,所以外部指標(biāo)行不通。 其次,指數(shù)為0.55的結(jié)果是否一定比0.51的好呢?技術(shù)上最好,也許業(yè)務(wù)上完全行不通,自己都覺得怪怪的,更沒法跟業(yè)務(wù)人員解釋。
這里貼一個(gè)筆者剛剛發(fā)現(xiàn)的CSDN相關(guān)文章,或許實(shí)用性更強(qiáng),有待研究。
3 距離計(jì)算
距離度量需要滿足非負(fù)性,同一性,對(duì)稱性和傳遞性。
對(duì)于有序?qū)傩裕畛S玫氖情h可夫斯基距離(Minkowski distance):

容易看出,p=1即為曼哈頓距離。p=2即為歐式距離。
無序?qū)傩钥刹捎肰DM(Value Difference Metric):

兩者混合即可處理混合屬性。
4 原型聚類
4.1 k均值算法(K-means)
K-means幾乎是聚類方法中最經(jīng)典的方法了。具體算法如下:

- Pros CSDN
- 原理比較簡單,實(shí)現(xiàn)也是很容易,收斂速度快
- 聚類效果較優(yōu)
- 算法的可解釋度比較強(qiáng)
- 主要需要調(diào)參的參數(shù)僅僅是簇?cái)?shù)k
- Cons
- K值的選取不好把握(改進(jìn):可以通過在一開始給定一個(gè)適合的數(shù)值給k,通過一次K-means算法得到一次聚類中心。對(duì)于得到的聚類中心,根據(jù)得到的k個(gè)聚類的距離情況,合并距離最近的類,因此聚類中心數(shù)減小,當(dāng)將其用于下次聚類時(shí),相應(yīng)的聚類數(shù)目也減小了,最終得到合適數(shù)目的聚類數(shù)。可以通過一個(gè)評(píng)判值E來確定聚類數(shù)得到一個(gè)合適的位置停下來,而不繼續(xù)合并聚類中心。重復(fù)上述循環(huán),直至評(píng)判函數(shù)收斂為止,最終得到較優(yōu)聚類數(shù)的聚類結(jié)果)
- 對(duì)于不是凸的數(shù)據(jù)集比較難收斂(改進(jìn):基于密度的聚類算法更加適合,比如DESCAN算法)
- 如果各隱含類別的數(shù)據(jù)不平衡,比如各隱含類別的數(shù)據(jù)量嚴(yán)重失衡,或者各隱含類別的方差不同,則聚類效果不佳
- 采用迭代方法,得到的結(jié)果只是局部最優(yōu)
- 對(duì)噪音和異常點(diǎn)比較的敏感(改進(jìn)1:離群點(diǎn)檢測的LOF算法,通過去除離群點(diǎn)后再聚類,可以減少離群點(diǎn)和孤立點(diǎn)對(duì)于聚類效果的影響;改進(jìn)2:改成求點(diǎn)的中位數(shù),這種聚類方式即K-Mediods聚類(K中值))
- 初始聚類中心的選擇(改進(jìn)1:k-means++;改進(jìn)2:二分K-means,相關(guān)知識(shí)詳見這里和這里)
- Code Sklearn
from sklearn.cluster import KMeansnkmeans = KMeans(n_clusters=2, random_state=0).fit(X)nkmeans.labels_nkmeans.cluster_centers_
4.2 高斯混合聚類(Gaussian Mixture Model, GMM)
采用概率模型來表達(dá)聚類原型。這里再次涉及到大量推導(dǎo),戳知乎
5 密度聚類
基于密度的聚類(density-based clustering)假設(shè)聚類結(jié)構(gòu)能通過樣本分布的緊密程度確定。 代表算法是DBSCAN(Density-Based S-patial Clustering of Applications with Noise)。
該算法定義的一個(gè)簇為由密度可達(dá)關(guān)系導(dǎo)出的最大密度相連樣本集合。

原理詳情戳簡書
- Code Sklearn
from sklearn.cluster import DBSCANnclustering = DBSCAN(eps=3, min_samples=2).fit(X)nclustering.labels_
- Pros Aandds Blog
- 相比K-means算法和GMM算法,DBSCAN算法不需要用戶提供聚類數(shù)量。
- DBSCAN能分辨噪音點(diǎn),對(duì)數(shù)據(jù)集中的異常點(diǎn)不敏感。
- Cons
- 如果樣本集的點(diǎn)有不同的密度,且該差異很大,這時(shí)DBSCAN將不能提供一個(gè)好的聚類結(jié)果,因?yàn)椴荒苓x擇一個(gè)適用于所有聚類的 (?,MinPts) 參數(shù)組合。注:OPTICS(Ordering Points To Identify the Clustering Structure)是DBSCAN算法的變種,它能較好地處理樣本密度相差很大時(shí)的情況。
- 它不是完全決定性的算法。某些樣本可能到兩個(gè)核心對(duì)象的距離都小于 ? ,但這兩個(gè)核心對(duì)象由于不是密度直達(dá),又不屬于同一個(gè)聚類簇,這時(shí)如何決定這個(gè)樣本的類別呢?一般來說,DBSCAN采用先來后到,先進(jìn)行聚類的類別簇會(huì)標(biāo)記這個(gè)樣本為它的類別。注:可以把交界點(diǎn)視為噪音,這樣就有完全決定性的結(jié)果。
6 層次聚類(Hierarchical clustering)
層次聚類試圖在不同層次對(duì)數(shù)據(jù)集進(jìn)行劃分,形成樹形聚類結(jié)構(gòu)。劃分可采用自底向上的策略,也可以采用自頂向下的策略。
AGNES(AGglomerative NESting)是一種自底向上的算法。它先將每個(gè)樣本看作一個(gè)初始聚類簇,然后每一步找尋最近的兩個(gè)簇進(jìn)行合并。不斷重復(fù)直到預(yù)設(shè)聚類數(shù)。

數(shù)據(jù)量小的時(shí)候,筆者還是很喜歡該類算法的,因?yàn)樯傻臉錉顖D(dendrogram)很好看:
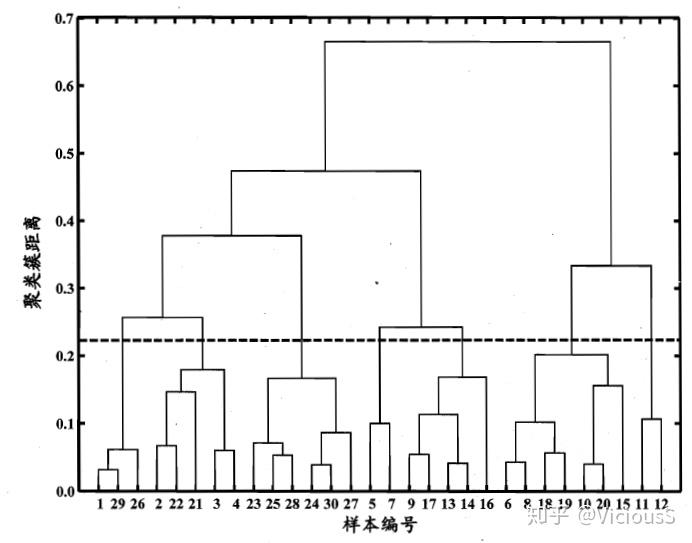
可惜數(shù)據(jù)量大的時(shí)候就只剩下密密麻麻的直線了。
- Code Stackabuse
from scipy.cluster.hierarchy import dendrogram, linkagenfrom matplotlib import pyplot as pltnnlinked = linkage(X, 'single')nnlabelList = range(1, 11)nnplt.figure(figsize=(10, 7))ndendrogram(linked,n orientation='top',n labels=labelList,n distance_sort='descending',n show_leaf_counts=True)nplt.show()
面試問題
- 描述K均值算法 Describe the k-means algorithm.
- 什么是高斯混合模型 What is the Gaussian Mixture Model?
- 對(duì)比高斯混合模型和高斯判別分析 Compare Gaussian Mixture Model and Gaussian Discriminant Analysis.
References
- 基于sklearn的聚類算法的聚類效果指標(biāo)
- k-means 的原理,優(yōu)缺點(diǎn)以及改進(jìn)
- [聚類四原型聚類]之高斯混合模型聚類
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Hierarchical Clustering with Python and Scikit-Learn








