工業(yè)蒸汽預(yù)測(cè)
項(xiàng)目背景使用脫敏后的鍋爐傳感器采集的數(shù)據(jù),預(yù)測(cè)鍋爐產(chǎn)生的蒸汽量。可以判斷預(yù)測(cè)的結(jié)果是連續(xù)性數(shù)值變量,屬于回歸預(yù)測(cè)求解一、數(shù)據(jù)
項(xiàng)目背景
使用脫敏后的鍋爐傳感器采集的數(shù)據(jù),預(yù)測(cè)鍋爐產(chǎn)生的蒸汽量。可以判斷預(yù)測(cè)的結(jié)果是連續(xù)性數(shù)值變量,屬于回歸預(yù)測(cè)求解
一、數(shù)據(jù)探索
1.1使用pandas的read_scv函數(shù)讀取訓(xùn)練集與測(cè)試集,并且使用info與describe函數(shù)查看
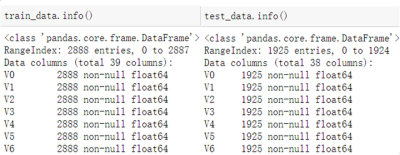
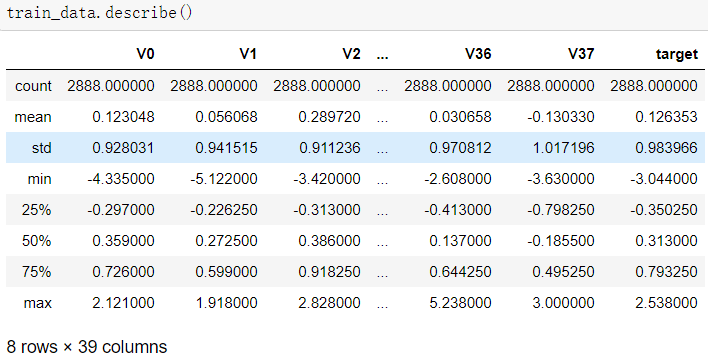
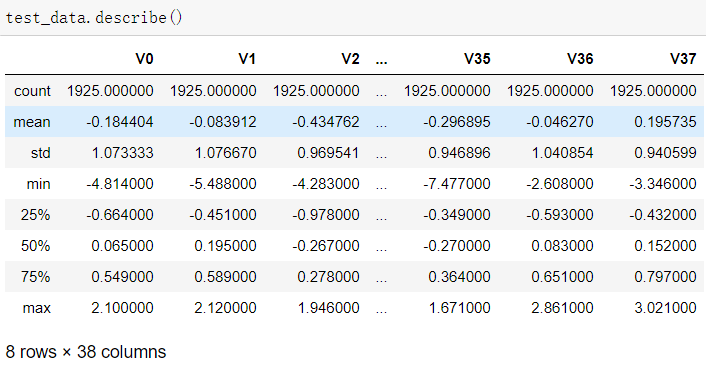
可以發(fā)現(xiàn),訓(xùn)練集有2888個(gè)樣本,測(cè)試集有1925個(gè)樣本;特征變量相同,為V0~V37共38個(gè)(由于數(shù)據(jù)采取了脫敏處理,特征的具體含義不明),訓(xùn)練集比測(cè)試集多了一個(gè)target項(xiàng)。數(shù)據(jù)類(lèi)型為浮點(diǎn)型,變量為數(shù)值型與連續(xù)型。
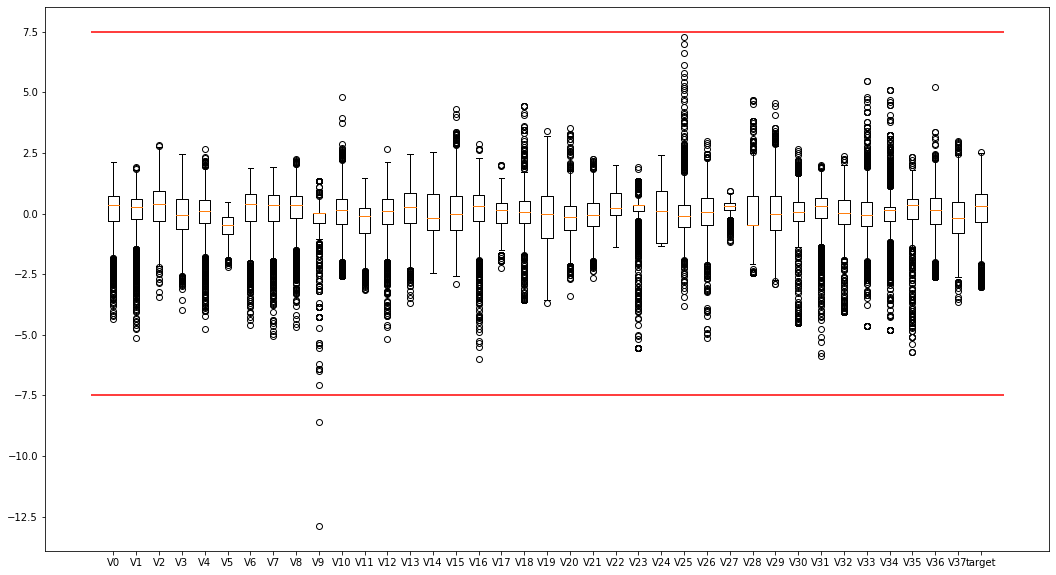
1.2使用箱線(xiàn)圖查觀察特征的數(shù)值分布

如圖,發(fā)現(xiàn)較多偏離值,許多特征的點(diǎn)位于四分位外,尤其是V9,可以考慮移除
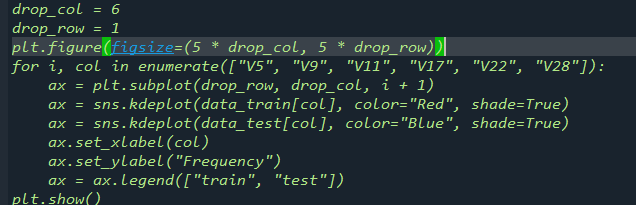
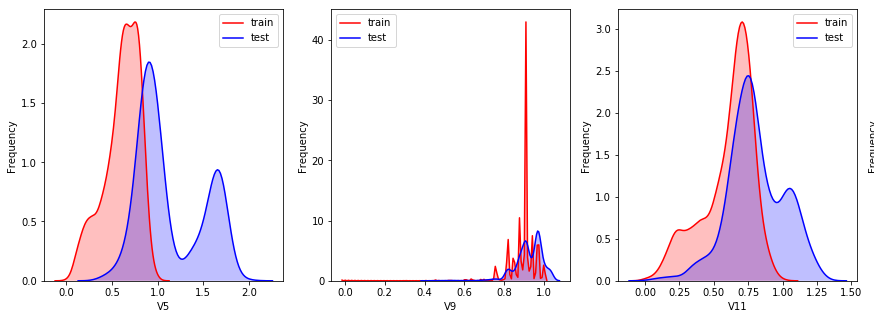
1.3通過(guò)繪制KDE分布圖,比對(duì)訓(xùn)練集與測(cè)試集中的特征變量的分布情況
對(duì)比后我們發(fā)現(xiàn):特征V5、V9、V11、V17、V22,V28的值在訓(xùn)練集測(cè)試集中分布差異較大,會(huì)影響模型泛化能力,需要?jiǎng)h除。

1.4使用直方圖、Q-Q圖來(lái)觀察特征的分布是否近似靜態(tài)分布,并且使用線(xiàn)性關(guān)系圖來(lái)觀察特征與tager是否構(gòu)成線(xiàn)性關(guān)系

從中可以看出,特征的情況有多種的排列組合,例如有的特征分布符合正態(tài),可以考慮對(duì)齊進(jìn)行Box-Cox變換,還有的特征與tager線(xiàn)性相關(guān)很差,就要考慮到使用非線(xiàn)性相關(guān)模型開(kāi)處理
1.5以熱力圖的方式,展現(xiàn)特征之間的相關(guān)性
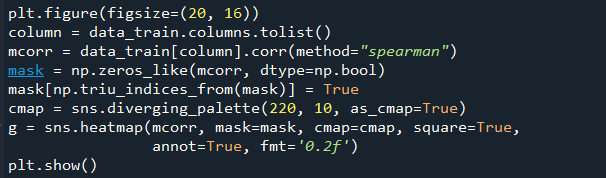
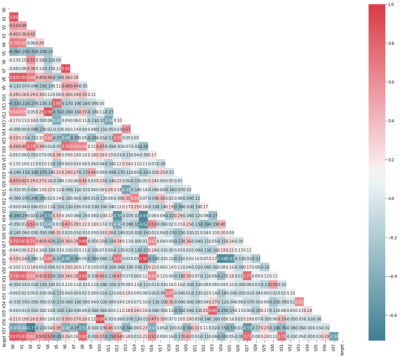
從圖中可以看出,在這37個(gè)特征之間,擁有著的強(qiáng)相關(guān)性不在少數(shù)。例如:V8、V27、V31就分別跟V0、V1有著強(qiáng)的正關(guān)(0.75以上);V15就跟V24、V25有著強(qiáng)負(fù)相關(guān)(-0.6以上),目測(cè)類(lèi)似的還有十幾組,這會(huì)導(dǎo)致共線(xiàn)性影響的概率增大,從而影響模型精度。所以可以考慮使用PCA對(duì)數(shù)據(jù)進(jìn)行處理,去掉多重共線(xiàn)性
二、特征工程
能夠確定下來(lái)的步驟,就是對(duì)數(shù)據(jù)進(jìn)行歸一化處理,然后刪除訓(xùn)練集與測(cè)試集分布不一致的特征,至于下一步的處理,得參考模型的MSE,于是建立一個(gè)bagging的集成模型來(lái)模擬最終模型(stacking的集成),使用GBDT、隨機(jī)森林、XGB作為基模型,采用5折交叉驗(yàn)證的方式,對(duì)訓(xùn)練集進(jìn)行試跑分。
1.1只進(jìn)行歸一化處理,刪掉分布不一致的特征,得到的MSE為:0.1323
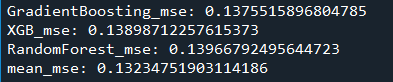
1.2在1.1的基礎(chǔ)上,對(duì)數(shù)據(jù)進(jìn)行Box-Cox變換,得到的MSE為:0.1321
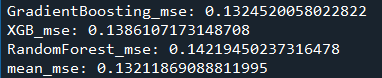
1.3,在1.2的基礎(chǔ)上對(duì)數(shù)據(jù)進(jìn)行PCA降維,保留原來(lái)特征90%信息,得到的MSE為:0.1587

運(yùn)行后,只剩下了16個(gè)主特征,但是MSE反而升高了,所以舍棄這步驟.
1.4,在1.2的基礎(chǔ)上,對(duì)數(shù)據(jù)進(jìn)行對(duì)數(shù)處理,使特征更符合正態(tài)分布,得到的MSE為:0.1332

1.5在1.4的基礎(chǔ)上,對(duì)數(shù)據(jù)進(jìn)行PCA降維,保留原來(lái)特征90%信息,得到的MSE為:0.1585

最終選擇1.2的步驟
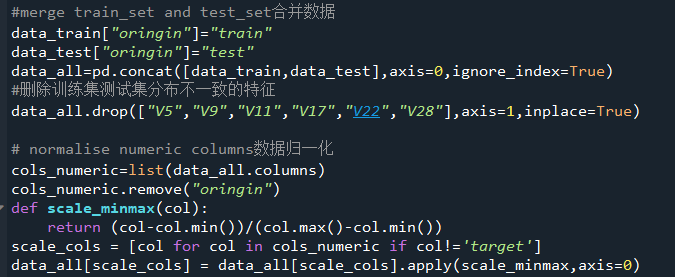

評(píng)估用的模型在:算法評(píng)估.py

處理后的數(shù)據(jù),另存為新文件

四、訓(xùn)練模型
項(xiàng)目為阿里天池競(jìng)賽,根據(jù)經(jīng)驗(yàn)一般,使用Xgboost、Lightgbm以及集成模型的得分較高,固不考慮單模型。
采用stacking的形式進(jìn)行模型融合,分成兩層。第一層由若個(gè)基模型組成,這里選擇了隨機(jī)森林跟GBDT,其輸入為原始訓(xùn)練集,每一個(gè)模型采用5折交叉來(lái)訓(xùn)練模型,形成了對(duì)整一個(gè)訓(xùn)練數(shù)據(jù)的標(biāo)簽的預(yù)測(cè),然后預(yù)測(cè)結(jié)果按順序堆疊起來(lái)——以此作為新的訓(xùn)練集的特征;使用4折預(yù)測(cè)出來(lái)的模型,對(duì)測(cè)試集進(jìn)行預(yù)測(cè),多少折模型就有多少份預(yù)測(cè),然后對(duì)這些預(yù)測(cè)取平均值——以此作為新的測(cè)試數(shù)據(jù)的標(biāo)簽。
基模型訓(xùn)練完畢后,把訓(xùn)練后的結(jié)果作為1個(gè)特征,這里就有了兩個(gè)新“特征”,與原始特合并后,這樣可以使模型的效果更好,還可以防止過(guò)擬合
第二層的模型選用lightgbm,則是以第一層基模型的輸出新訓(xùn)練集進(jìn)行訓(xùn)練,并且以新數(shù)據(jù)標(biāo)簽進(jìn)行交叉驗(yàn)證,然后得到完整的stacking模型,最后對(duì)數(shù)據(jù)進(jìn)行預(yù)測(cè)。
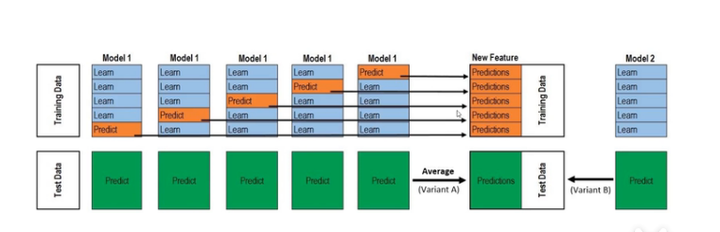

訓(xùn)練過(guò)程
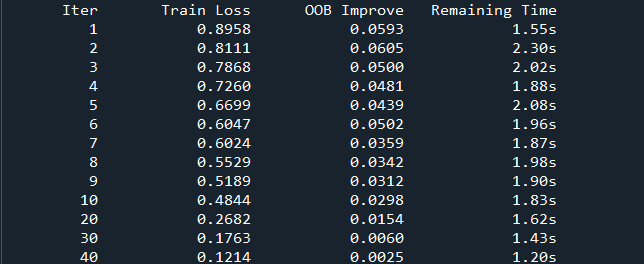
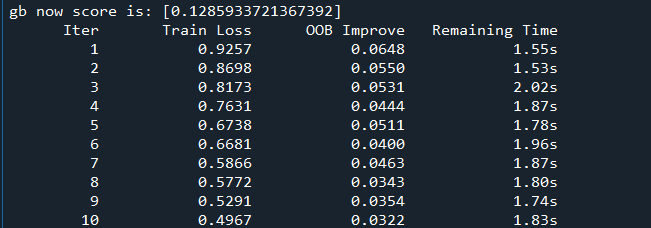
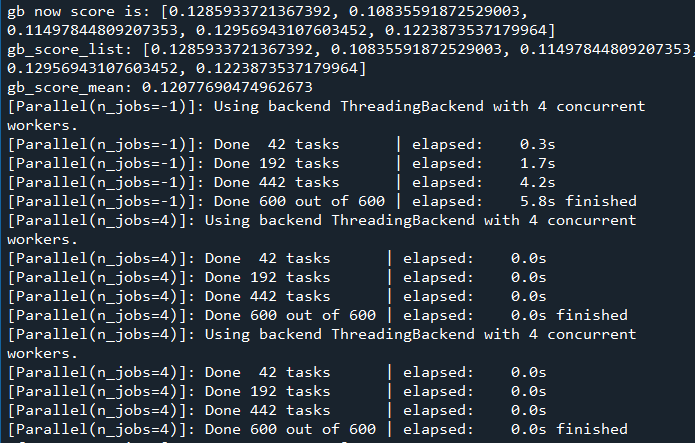
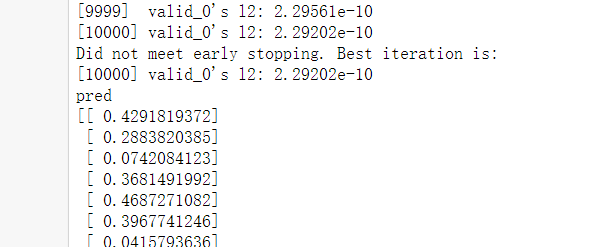
打印結(jié)果
代碼、數(shù)據(jù)鏈接如下
熟練工人/工業(yè)蒸汽預(yù)測(cè)上一篇:成都流云
下一篇:漁夫的野望:熱泵蒸汽機(jī)








