GPT-2的信息泄漏問題
前段時間有篇論文講如何從語言模型中抽取知識圖譜,今天就看到了一篇論文題目說要從語言模型中抽取訓練數據。我帶著好奇打開了論文
前段時間有篇論文講如何從語言模型中抽取知識圖譜,今天就看到了一篇論文題目說要從語言模型中抽取訓練數據。
我帶著好奇打開了論文,結果被一眾知名機構亮瞎了雙眼,來一起感受下:

懷著敬畏的心看完了摘要,原來是探討GPT-2中信息泄漏的,作者直接從GPT-2中榨出了個人隱私,還有手機號的那種:
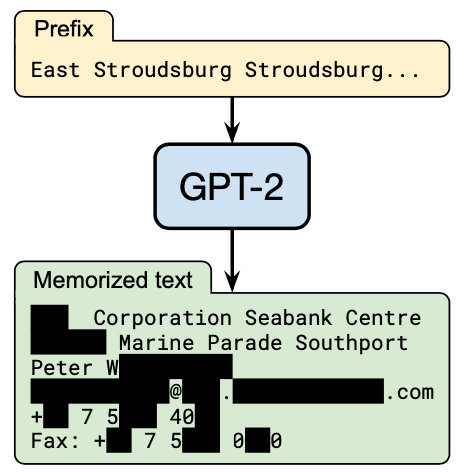
不由得有些心疼GPT-2,小小年紀,就因為記憶力太過強悍而被這么多大佬逼問。
Anyway,打是疼罵是愛,信息泄漏的問題還是要好好研究一下,真要是拿用戶的私人對話數據精調,生成結果帶有別人的隱私可就涼了。
那么,下面rumor就帶大家看看作者是如何從GPT-2中抽取數據的~
論文題目:Extracting Training Data from Large Language Modelsn論文地址:https://arxiv.org/abs/2012.07805
Eidetic Memory
Eidetic Memory可以翻譯成過目不忘,抽出哪些query才能證明模型有過目不忘的能力呢?作者先進行了定義:當我們根據prefix生成一段句子s后,去評估s在訓練樣本中出現的次數,越少就說明模型記憶能力越強。
評估流程
明確了定義之后,就要去抽出符合條件的樣本進行證實。作者攻擊GPT-2的整體流程如下圖,先用模型生成候選樣本,再根據指標排序選出可能是硬記的句子,之后通過搜索結果是否完全匹配進行驗證。
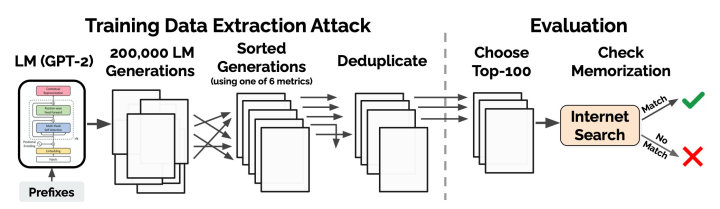
下面詳細介紹下每步的策略。
生成候選樣本
作者使用了3個策略,用每個策略生成200,000個256長度的樣本:
- Top-n:輸入起始字符,基于Top-k的解碼策略生成。但這種方法的結果有很多重復,作者又提出了兩個改進策略提示多樣性
- Temperature:在計算softmax預測下一個token時,增加超參數temperature讓置信度更加平滑。為了提示多樣性,在產生前20個token時將 t 從10逐漸降到 1,這樣可以保證模型后續對結果的自信
- Internet:參考GPT2訓練語料的收集,對Common Crawl進行清洗,并隨機選取5-10個token作為prefix生成結果
候選樣本排序
對于上述策略生成的結果,采用以下六種策略選取要評估的句子:
- Perplexity:計算樣本的perplexity,研究分數低的樣本。但單純計算困惑度的話,某些子串重復多次的困惑度也很低,于是作者又提出了以下5個metric,幫助結果篩選
- Small:計算大模型和小模型的log困惑度的比例。小模型的記憶力差,去算大模型硬記的句子肯定很困惑,所以用不相關的語料訓練一個更小的語言模型,過濾掉在GPT2和小語言模型上似然都很高的樣本
- Medium:計算大模型和中模型的log困惑度的比例
- zlib:用zlib entropy作為輔助指標(用zlib壓縮文本后的大小),可以去掉重復的子串
- Lowercase:將句子轉小寫后再計算一次困惑度,計算原困惑度與小寫困惑度的比例。因為硬記下來的大小寫是固定的,換了之后困惑度會大幅變化
- Window:GPT-2在50個token的滑動窗口上的最小困惑度。因為在生成的文本中,可能是被硬記住的(低困惑度)和其他的(高困惑度)混在一起
評估
上述生成-選擇的策略一共有3x6=18種,每個策略作者選擇了100個候選。再通過trigram的重合度進行去重。
之后四個作者會分別借助搜索引擎,對1800個樣本進行評估,如果能搜到完全匹配的結果就說明該樣本是GPT2硬記的,最后將這些樣本跟GPT-2的作者進行確認。
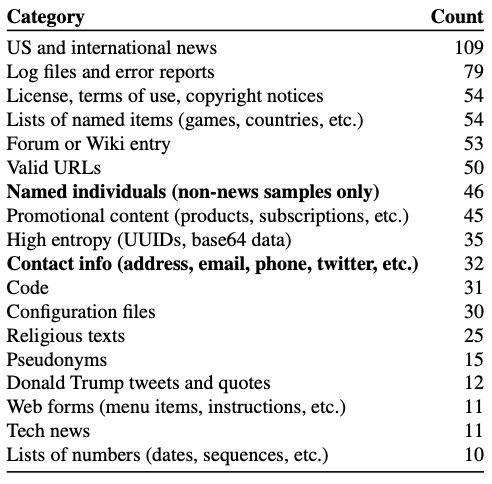
**最終在1800個候選中發現了604個被死記硬背的樣本。
對604個樣本的分類如下:
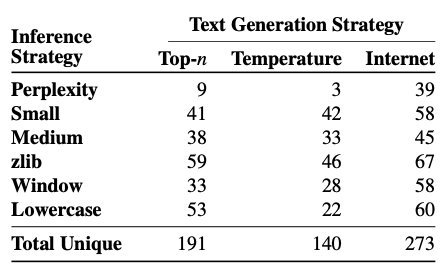
對比不同策略,可以發現從Internet取prefix的結果普遍更好。且困惑度這個指標不太可信:
作者之后也嘗試了提取更長的樣本,最長提取到了1450行的代碼片段。
減少LM的信息泄漏
那么,怎樣才能減少信息泄漏呢?作者提供了以下策略:
- 差分隱私(Differential Privacy),通過增加噪聲讓輸出結果隨機化。但這樣會降低模型精度,同時這個算法需要一些label,適配到web數據需要進行改動
- 處理訓練語料,去除敏感信息;段落去重
- 用現有的方法及時檢查模型的隱私等級
總結
作者通過很簡單的方法,證實了語言模型雖然沒有過擬合,但也會對某些數據死記硬背,并且有隱私泄漏的風險。同時越大的模型記住的數據越多(1.5B參數的GPT-2比124M的GPT-2多記了18倍數據)。
模型的隱私數據泄漏、性別種族歧視問題其實一直都是存在的,但大多數使用者只看到了模型管用的一面,在應用中確實沒有注意到這些風險。這次大佬們也是給大家敲醒了一次警鐘,畢竟生成模型的結果還是很不可控的,之后在訓練時一定要注意語料中的這些問題,與君共勉。









