剔除集合中過(guò)大過(guò)小的異常值
一個(gè)集合X中可能存在過(guò)大或過(guò)小的異常值,希望計(jì)算一個(gè)范圍,剔除集合X中過(guò)大或過(guò)小的異常值,這個(gè)范圍的上下限就是閾值,較大值稱為閾值
一個(gè)集合X中可能存在過(guò)大或過(guò)小的異常值,希望計(jì)算一個(gè)范圍,剔除集合X中過(guò)大或過(guò)小的異常值,這個(gè)范圍的上下限就是閾值,較大值稱為閾值上限,記為threshold_up,較小值稱為閾值下限,記為threshold_down。
X=[x1,x2,…,xn]
算法原理
集合中只有少數(shù)是異常值,如果把X中的點(diǎn)看作空間中的點(diǎn),則某個(gè)點(diǎn)距離其他點(diǎn)都很遠(yuǎn)時(shí)認(rèn)為該點(diǎn)是異常值,正常值取值范圍就是正常值中最小值到最大值的范圍。
計(jì)算過(guò)程
1. 計(jì)算每個(gè)xi與其他所有值的絕對(duì)差的和,稱為半徑,記為R。
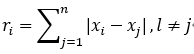
其中ri是半徑序列R的第i個(gè)元素。
2. 記錄下R中的元素從小到大排序后的索引序列,記為R_psort。
3. 最小半徑min_r和最大半徑max_r
min_r=RR_psort(1)
max_r= RR_psort (-1)
其中R_psort(1)是R_psort序列中的第一個(gè)(同R_psort1),R_psort(-1) 是R_psort序列中的最后一個(gè)。
4. 如果max_r比min_r大一個(gè)數(shù)量級(jí)(max_r≥min_r*10)則把大于min_r*5以上的半徑對(duì)應(yīng)的xi剔除。
(1) 大于min_r*5的索引min_r5_pos
min_r5_pos=j,RR_psort(j)≥min_r*5
(2) 按索引剔除X序列中的數(shù),得到X_new
X_new=XXR_psort(j≥min_r5_pos)
其中R_psort(j≥min_r5_pos)是R_psort中所有不小于min_r5_pos的索引集合。
(3) 用X_new重復(fù)1,2,3,4,直到不滿足max_r≥min_r*10。
5. 設(shè)最小半徑的倍數(shù)為n(默認(rèn)n=2,n≤5),稱為半徑倍數(shù),找到半徑大于min_r*n的索引min_rn_pos
min_rn_pos= j,RR_psort(j)>min_r*n
6. min_rn_pos之前的xi為正常值序列,稱為閾值序列,記為X_normal
X_normal=XR_psort (j≤min_rn_pos-1)
7. 計(jì)算閾值上下限threshold_up和threshold_down
threshold_up= max(X_normal)
threshold_down= min(X_normal)
寫出代碼:
| A | B | C | D | |
| 1 | =seq | /集合X | ||
| 2 | =up_down | /上限或下限 | ||
| 3 | =n | /半徑倍數(shù)n | ||
| 4 | =func(A7,seq,up_down,n) | |||
| 5 | return A4 | /返回結(jié)果 | ||
| 6 | /計(jì)算閾值,參數(shù):序列,上限或下限,半徑 | |||
| 7 | func | |||
| 8 | =if(B7=="up",func(A10,A7,C7),func(A15,A7,C7)) | /如果取上限就取閾值序列的最大值,下限就取閾值序列的最小值 | ||
| 9 | /計(jì)算閾值上限 | |||
| 10 | func | |||
| 11 | =A10.select(~) | /過(guò)濾 null | ||
| 12 | if B11==[] | return null | ||
| 13 | =func(A20,B11,B10).max() | /X_normal.max() | ||
| 14 | /計(jì)算閾值下限 | |||
| 15 | func | |||
| 16 | =A15.select(~) | /過(guò)濾 null | ||
| 17 | if B16==[] | return null | ||
| 18 | =func(A20,B16,B15).min() | / X_normal.min() | ||
| 19 | /計(jì)算閾值序列,參數(shù):序列,半徑倍數(shù) | |||
| 20 | func | |||
| 21 | =A20.((v=~,A20.(abs(v-~))).sum()) | /R | ||
| 22 | =B21.psort() | /R_psort | ||
| 23 | if B21(B22(1))*10<B21(B22.m(-1)) | =B22.pselect(B21(~)>=B21(B22(1))*5) | /如果 max_r>min_r*10min_r5_pos | |
| 24 | =A20(A20(B22.m(C23:))) | /去掉大于 min_r*5 的值 | ||
| 25 | return func(A20,C24,B20) | |||
| 26 | else | =B21(B22(1))*B20 | /min_r*n | |
| 27 | =(gt_min=B22.pselect(B21(~)>C26),if(!gt_min,A20.len(),gt_min-1)) | /min_rn_pos | ||
| 28 | =A20(B22.to(C27)) | /X_normal |
輸入?yún)?shù)說(shuō)明:
1. A1中的seq是輸入集合X;
2. A2中的up_down是計(jì)算上限還是下限的參數(shù)。
up_down=“up”時(shí),計(jì)算閾值上限;
up_down=“down”時(shí),計(jì)算閾值下限。
3. A3中的n是半徑倍數(shù)n;
2≤n≤5
n越大正常值的取值范圍越大,即閾值上限越大,閾值下限越小。
算法效果實(shí)例
1. 把集合X和不同半徑倍數(shù)n條件下的閾值上下限畫在圖上如下:

圖中橫軸是每個(gè)值的索引,縱軸是X中值的大小。圖右側(cè)的圖例說(shuō)明
X:集合X
X_n2_up:n=2時(shí)的閾值上限
X_n2_down:n=2時(shí)的閾值下限
X_n2.5_up:n=2.5時(shí)的閾值上限
X_n2.5_down:n=2.5時(shí)的閾值下限
X_n3_up:n=3時(shí)的閾值上限
X_n3_down:n=3時(shí)的閾值下限
不大于閾值上限且不小于閾值下限的值就是X中的正常值。
http://www.raqsoft.com.cn/wx/course-data-mining.html








