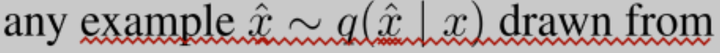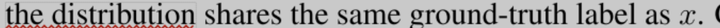UAD Unsupervised Data Augmentation
發布時間:
本文得出的結論是,用在有標簽數據上增強效果好的方法,用在無標簽數據上也好在數據增廣的時候,假如剛好截取了沒有貓的背景部分, 生成
本文得出的結論是,用在有標簽數據上增強效果好的方法,用在無標簽數據上也好
在數據增廣的時候,假如剛好截取了沒有貓的背景部分, 生成新的訓練數據 x'。此時 x' 的標簽與 x 不同。強迫神經網絡對 x 和 x' 都預測為貓, 毫無意義。UDA 緊抓這一點,使用智能增廣技術,AutoAugment,使得數據增廣不破壞標簽.
Training Signal Annealing技術,來防止有標簽數據過擬合。具體來說,如果一個有標簽數據的預測概率超過了當前閾值,那么在這次計算loss時就不算它的了(因為它已經表現很好了,再訓練也不過是過擬合而已)。
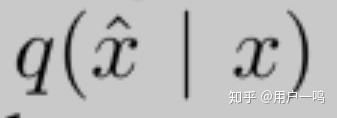
augmentation transformation from which one can draw augmented examples x? based on an original example x