Tage預測器
一、Tage預測器前身TAGE分支預測是綜合O-GEHL分支預測和PPM-like分支預測所設計的分支預測算法。由base predictor T0,和一序列(par
一、Tage預測器前身
TAGE分支預測是綜合O-GEHL分支預測和PPM-like分支預測所設計的分支預測算法。由base predictor T0,和一序列(partially)tagged predictor components Ti組成,tagged predictor components Ti所采用索引歷史長度是不同的,成幾何長度關系。
而TAGE,就像他名字寫的那樣,有兩個特征讓他的accuracy很高:
- TA(Taged)
目前分支預測的索引一般為PC或者PC和global history的xor,出于存儲效率考慮,只有一部分會用于索引,會有aliasing。這個時候如果把多余的PC存起來做tag,就能更好地比對出哪些是真match,哪些是aliasing,有助于選取到真正對應的entry。
2. GE(Geometrical)
主流觀點認為一般global history match的長度越多,預測就越準確。所以TAGE選取了幾何增長的history長度,如32,64,128,256。原則上,每次優先選取最長的match做預測。當然也有一些簡單地branch可能不需要那么長,短的就好。TAGE的userful counter 就發揮了作用。如果短的history predict的效果就很好,就會通過userful counter 反映出來。
1. O-GEHL預測器
TAGE預測器比O-GEHL預測器的硬件復雜度更低(不使用動態歷史長度擬合,更短的全局歷史)。同時,在相同的存儲預算和相同的預測器復雜度下,TAGE預測器優于O-GEHL預測器。

(1)結構
- 由多個預測表組成,每個表由PC和不同長度的歷史和指令地址共同索引。其中歷史長度呈幾何級數
- 最終的預測通過加法樹得出。
- 在GEHL的基礎上增加動態歷史長度自適應和閾值調整
(2)預測
預測是通過將預測表上讀取的預測相加來計算的,其中M是表項的個數,C(i)是每個表項的有符號飽和計數器,假設計數器的寬度是兩位,那么C(i)的最大值是1,最小值是-2。
S = M2 +
C(i) ------ 當S>0時則預測跳轉,當S<0則預測不跳轉
(3)更新
GEHL預測器更新策略來源于感知器預測器更新策略,GEHL預測器僅在預測錯誤或計算的和S的絕對值小于閾值( 
if (( p! = Out ) or ( |S| <
for each i in parallel
if Out then C(i) = C(i) + 1 else C(i) = C(i) - 1
(4)自適應閾值
且對于大多數benchmark,閾值的質量與錯誤預測的更新次數 

基于此,采用一個7-bit 飽和計數器TC,提出如下閾值自適應算法:
if((p!=out))n{n TC=TC+1;n if(TC==SaturatedPositive)n ??θ=θ+1;TC=0;n}nif((p==out)&(|s|≤θ))n{n TC=TC-1;n if(TC==SaturatedNegative)n ??θ=θ-1;TC=0;n}n
(5)動態歷史長度自適應
基于對表 T7 上更新時的混疊率的粗略估計,采取動態選擇歷史長度以索引預測器的算法。
例如,一個O-GEHL有8個表,11種歷史長度,使其中三個表對應兩種可用的歷史長度,即T2:L(2),L(8);T4:L(4),L(9);T6:L(6),L(10)。表 T7 是除了 L(8)、L(9) 和 L(10) 以外使用最長歷史間隔的預測器組件。 直觀地說,如果表 T7 出現高度混疊,則應在表 2、4 和 6 上使用短歷史; 另一方面,如果表 T7 遇到低度混疊,則應使用長歷史記錄。
動態估計T7的混疊率:在T7的某些項上增加 tag-bit,用一個單獨的9-bit 飽和計數器AC
在預測器更新時,tag-bit 記錄分支pc的一位(最低位),然后執行以下算法:
if((p!=out)&(|S|≤θ))n{n if((PC&1)==Tag[indexT[7]])n AC++;n else AC=AC-4;n if(AC==SaturatedPositive) Use Long Historiesn if(AC==SaturatedNegative) Use Short Historiesn Tag[indexT[7]]=(PC&1);n}n
當使用相同的(分支,歷史)對對執行表 T7 中相應條目最后更新時,AC 遞增。 當最后一次更新由另一個(分支,歷史)對執行時,AC 減少 4。
2. PPM-like預測器
TAGE分支預測器直接源于PPM-like基于tag的分支預測器。
TAGE與PPK-like不同之處在于:
1.使用幾何歷史長度序列
2.一種新的高效預測器更新算法

(1)結構
由多個banks組成。
第一個bank是一個基礎預測器(一個雙模態預測器),單由PC索引,包括3位的飽和計數器和1位的m bit,m表示meta-predictor即元預測器。
其余banks由PC和不同長度的全局歷史位共同索引,每一項包括3位飽和計數器、8位tag和1位的u bit。u bit表示useful entry,
其余banks中PC和全局歷史一方面hash確定索引bank中的哪一項(圖中的10bit),另一方面hash計算tag,看計算的tag和索引項中的8-bit tag是否匹配 。
當全局歷史位超出索引位長度時,對全局歷史位進行折疊,稱為歷史折疊(history folded)。
(2)預測
預測時同時訪問所有預測器,如果其余banks中由tag匹配,則使用tag匹配的banks進行預測,如果有多個tag命中,則采用歷史長度最長的bank的預測;如果沒有匹配的tag,則使用基礎預測器預測。
(3)更新

預測正確:則不必分配新項。
預測錯誤:bank X最終提供預測,若X≤3且預測錯誤,則在banks n>X中分配一項或多項。取bank X+1 到 bank 4的對應項的u bit, 替換其中u=0的項,若無,從中任意選取一項替換。
填充規則:tag填充該bank哈希出的8bit tag;u填充0;ctr填充100或011,選擇規則如下:
讀取bank0對應項的m:
若為1,看bank X預測結果是taken還是not taken,taken填充100,not taken填充011。
若為0,看bank 0預測結果是taken還是not taken,taken填充100,not taken填充011。
(4)更新原理
更新m-bit和u-bit原理:
若最終預測不同于雙模態預測,有如下兩種情況:
1. 最終預測正確,雙模態預測錯誤:u-set,m-set
此時說明當前分支與當前全局歷史相關性強,提供最終預測的bank有用,故其u-bit set;
m-bit set表示當為該分支分支新項時其飽和計數器應初始化為最終預測(正確的預測)。
2. 最終預測錯誤,雙模態預測正確:u-reset,m-reset
此時說明提供最終預測的bank無用,故其u-bit reset;
當前分支與當前全局歷史相關性差,m-bit reset 表示為該分支分配新項時其飽和計數器應初始化為雙模態計數器的結果(正確的預測)。
二、Tage預測基本原理
1. Tage預測原理
TAGE分支預測器直接源于PPM-like基于tag的分支預測器。由base predictor T0,和一序列(partially)tagged predictor components Ti組成,tagged predictor components Ti所采用索引歷史長度是不同的,成幾何長度關系:

其中:
base predictor T0就是簡單的PC索引的2-bit飽和計數器。
tagged predictor components Ti 由3 bit的signed ctr(有符號計數器),tag,以及2bit的unsigned useful counter u組成。
其中:
pred:表示的是ctr項,用來預測是否進行跳轉
tag:用來保存pc和跳轉歷史哈希之后的結果,以便預測時判斷是否命中,一般在7-14可以取得好的效果,使用10或許是一個很好的權衡,同時,標簽的寬度應該(稍微)隨著歷史長度的增加而增加:在使用最長歷史的表上,錯誤的匹配更有害。
u:表示這個components 的置信度如何
預測計算方法跟PPM-like相似,若tag命中則取其中歷史長度最長的component的預測結果,若未命中,則取base predictor的預測結果。
一些有用的概念:
provider component: tag命中則取其中歷史長度最長的conponent,若無,即base predictor。
alternate component: 次一級tag命中的component,若無,即base predictor。
2. Tage更新策略
(1)更新useful counter u:
if provider pred != altpred, 更新provider component中對應項的u(置信度)(即預測正確+1,預測錯誤-1,在邊界則不變)
因為當altpred 和 provider 預測相同時,說明沒有必要用歷史更長的provider,用前者預測就足夠,因此不增加其有用計數器;當二者不同且后者正確時,說明provider是有用且必要的,因此增加其有用計數器。
此外,周期性重置所有的u為0,先重置高位,再重置低位。文中周期重置為256K branch(?)。
(2)預測成功或失敗時,更新ctr(counter)
預測正確時:更新provider component的ctr,當預測可信度較低時,也會更新alter提供者。
預測錯誤時:
1. 更新provider component的ctr
2. 分配新項(至多分配一項):
(1)如果provider不是最長的歷史項,則需在比提供預測組件歷史更長的且u-bit為空的組件中分配新項。
若provider component 為 Ti,讀T(i+1)至T(M-1)的對應項的u,若有u = 0,替換其中最低歷史長度的條目(條目)。若無,這些u = u -1。
(2)如果有兩個組件Tj和Tk(j < k)都可被分配((i.e., 

(3)初始化條目:填充的ctr為weak correct, u為0。
當最長的歷史命中條目是一個新分配的條目時,使用altpred作為預測比normal預測更有效。如果一個條目的有用計數器為空,并且它的預測計數器很弱(0或-1),我們就認為它是新分配的,我們的實驗表明,該屬性對于應用程序是全局的,可以通過單個4位計數器動態監控。
u-bit策略:在分配新項時,動態監控預測失誤后嘗試分配新項的成功和失敗次數,這種監控通過一個名為TICK的計數器實現。預測失誤時,相關項的u-bit可能遞會減,而遞減的概率隨著TICK計數器值的增加而增加。
當tag匹配的項的置信度計數器ctr為0時,altpred有時比正常預測更準確。因此在實現中使用一個4-bit計數器useAltCtr,動態決定是否在最長歷史匹配結果信心不足時使用備選預測。在實現中處于時序考慮,始終用基預測表的結果作為備選預測,這帶來的準確率損失很小。
備選預測邏輯的具體實現如下:
ProviderUnconf表示最長歷史匹配結果的信心不足。當provider對應的ctr值為0b100、0b011時,說明最長歷史匹配結果的信心很足,此時providerUnconf為false;當provider對應的ctr值為0b01、0b10時,說明最長歷史匹配結果的信心不足,此時providerUnconf為true。
3. 更新策略的基本原理
首先,更新策略的設計目的是最大限度地減少一次分支出現所引起的擾動。
為了最小化單個(分支,歷史)對的占用空間,在錯誤預測的情況下,最多分配一個帶標記的條目。
要分配的條目的選擇是通過有用的計數器來管理的,我們管理有用計數器有兩個目標,只有當自上次分配條目以來有一些正收益時,u的值才能為正:
- 保證最近有用的條目不會被重新分配
2. 通過在條目未被選中時減少u計數器和其優雅的重置,我們嘗試模擬偽最近最少策略
有用的計數器u被設置為強而無用: 在條目有效地幫助提供正確的預測之前,它是下一個替換的自然目標
有時需要多次訪問Tage預測表,即在預測時讀取所有預測器表,在提交時讀取所有預測器表,在更新時寫入(最多)兩個預測器表,但是,可以避免在提交時進行讀取。預測時可用的少量信息(提供組件的編號、提供組件的ctr和u值以及所有u計數器的0值),以便被檢查。
4. 一些問題
- 為什么要用不同長度的歷史?
既適用于有較長歷史的分支可以利用足夠多的歷史,又可以為歷史較短的分支或等待 warm up 的過程提供預測,當沒有較長歷史時仍可以采用已有的歷史進行預測
- 為什么用部分標記匹配而不是加法樹?
對于使用幾何序列歷史長度的預測器,部分標記匹配比加法樹更具成本效益。
- 為什么要及時更新預測表?
在處理器中,硬件預測器表在指令退休時更新,以避免被錯誤路徑污染。每個在正確路徑上的分支訪問3次預測期表:預測時讀、退休時讀、退休時寫,如此大量的訪問可能會導致非常昂貴的分支預測結構。

TAGE預測周期性的有規律的分支行為通常有效,即使周期長度橫跨數百甚至數千個分支。但如果一個循環體內的控制流路徑是不規律的,TAGE不能很好的預測循環退出分支。而循環預測器能夠通過迭代的次數更加有效地跟蹤循環,因此預測這些循環的退出分支非常有效。
- 為什么要用統計校正預測器?
一些應用上,一些分支行為與分支歷史或路徑相關性較弱,表現出一個統計上的預測偏向性。對于這些分支,相比TAGE,使用計數器捕捉統計偏向的方法更為有效。
- 為什么要使用局部歷史?
在一些應用中,有一些分支使用局部歷史比使用全局歷史能夠進行更好的預測。將SC中的全局歷史替換為局部歷史提供了一種平穩地將TAGE和局部預測器結合起來的方法。
三、ITTage預測器
ITTAGE預測器的原理主要用于預測間接跳轉指令。
與Tage相似,predictor有一個無標記的基礎預測器IT0,它負責提供默認預測和一組(部分)標記的預測器組件。
標記表上的條目由部分標記tag、跳轉目標Targ、置信位c和2位有用計數器u組成,在TAGE中表示預測的計數器被完整的目標地址Targ加上置信位c所取代,以獲得預測器上的一些遲滯。
主要的預測原理圖如下:
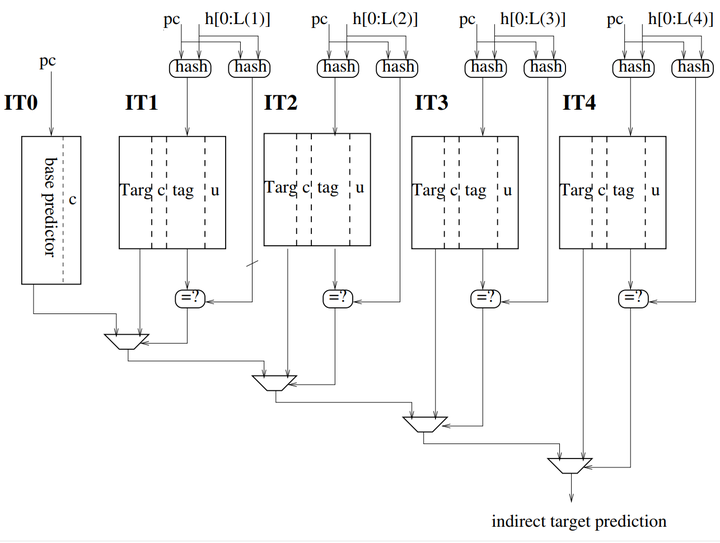
預測選擇算法直接繼承自TAGE預測器。預測器更新算法也繼承自TAGE更新算法。
如果發生命中,目標替換在基礎預測器和標記組件上,但錯誤預測是通過單個置信位控制的。
四、COTTAGE預測器
COTTAGE預測器實現了實現了TAGE預測器和ITTAGE預測器的組合,存儲條件跳轉預測和間接跳轉預測,同時標簽和索引計算邏輯也是共享的。在每個循環中,在同一行上讀取條件分支預測和間接跳轉預測。
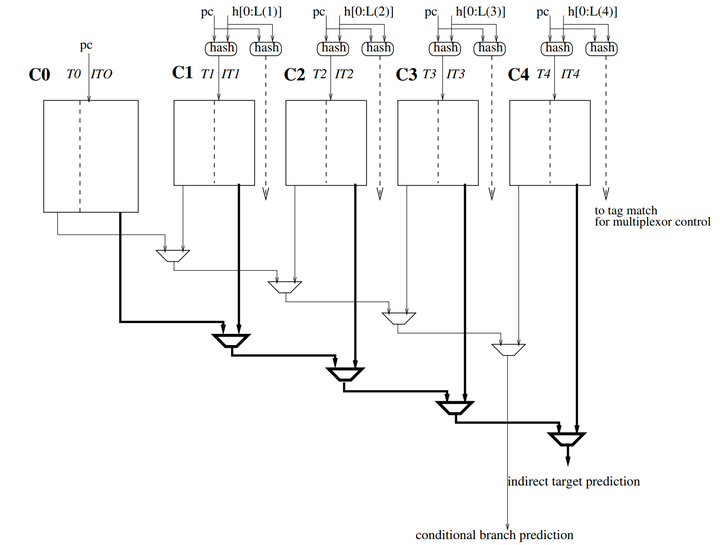
在高端超標量處理器上,所有的預測結構(條件分支預測器、間接跳轉預測器、返回堆棧、BTB)都必須投機性地訪問。TAGE預測器和ITTAGE預測器結構的相似性允許在單個物理結構中重新組合條件分支預測器和間接跳轉預測器。
為了成本效益,預測表必須實現更多的TAGE條目和ITTAGE條目。因此,預測表中的存儲一個間接跳轉預測和幾個條件分支預測。省略了在每個COTTAGE組件出口選擇正確的TAGE條目所需的多路復用器。
當考慮實現條件預測器和間接跳轉預測器的預測成本時,COTTAGE預測器似乎是一種具有成本效益的解決方案:一個5分量的COTTAGE預測器在總共只使用5個存儲表的情況下,對條件分支和間接跳轉都提供了最先進的預測精度。
五、TAGE-SC預測器
TAGE在預測非常相關的分支時非常有效,TAGE未能預測有統計偏向的分支,例如只對一個方向有小偏差,但與歷史路徑沒有強相關性的分支。TAGE-SC則負責預測具有統計偏向的條件分支指令并在該情形下反轉 TAGE 預測器的結果。
統計校正的目的是檢測不太可靠的預測并將其恢復,來自TAGE的預測以及分支信息(地址、全局歷史、全局路徑、局部歷史)被呈現給統計校正預測器,其決定是否反轉預測。
SC的預測算法依賴TAGE里面的是否有歷史表hit的信號provided,以及provider的預測結果taken,從而來決定SC自己的預測。provided是使用SC預測的必要條件之一,provider的taken作為choose bit,選出SC最終的預測,這是因為SC在TAGE 預測結果不同的場景下可能有不同的預測。
統計校正預測器的一個相當有效的實現源自GEHL預測器,它具有4個邏輯表,用4個最短歷史長度(0,6,10,17)作為主要的TAGE預測器,以及從TAGE預測器中流出的預測(已采取/未采取)。表項是1K的,每個6位的寬度,即總共24Kbit。

預測結果的計算方法是: 從統計校正表中讀取的預測結果(集中化處理)之和加上TAGE中命中庫輸出結果(集中化處理)的8倍。所謂集中預測,我們指的是2*ctr+1策略。
如果統計校正器預測器不一致且總和的絕對值高于動態閾值,則還原TAGE預測。
動態閾值在運行時進行調整,以確保使用Statistical Corrector預測器是有益的。用于適應閾值的技術類似于動態適應GEHL預測器更新閾值的技術。
A. 對于32Kbits的預測器
使用校正過濾器,實際上是一個關聯表,用于監控來自TAGE的錯誤預測,預測失誤(PC和預測方向)以低概率存儲在關聯表中。命中校正過濾器時,如果某項指示以高置信度恢復預測,則預測被反轉,但校正過濾器不會反轉從TAGE流出的高置信度的分支。
64-entry 2-way糾正器用于13-bit entry (6-bit counter + 7-bit tag)。作為一種優化,來自TAGE的高置信度分支不會被校正濾波器反轉,校正濾波器將總體錯誤預測率降低了約1.5%
B. 對于256Kbits的預測器
MGSC(multi-GEHL SC):由6個組件組成,1個偏置組件和5個GEHL-like組件。
返回堆棧相關分支歷史:歷史存儲在與調用相同的返回堆棧中。在調用時,堆棧的頂部被復制到堆棧中新分配的條目上,在相關的返回之后,分支歷史記錄反映了調用之前執行的分支。這允許捕獲在被調用函數的執行過程中可能丟失的一些相關性。
預測計算:統計校正預測器表上的預測結果之和的符號,加上GEHL表數量乘以方向(+1或-1)的兩倍。(不確定是不是這么回事兒)
MGSC預測表使用動態閾值策略進行更新,使用一個PC索引的動態閾值表
六、香山處理器
1. 第一個周期(uFTB)
uBTB可以直接解決jal和jalr的跳轉問題?
2. 第二個周期(FTB、TAGE)
(1)第一次更新時:
FTB:將最多(兩條分支指令)的起始地址和結束地址保存到FTB中作為一個預測塊。
情況1:如果一個預測塊中只觀測到一條分支指令,那么一個預測塊的大小是32Byte
情況2:如果一個預測塊中連續觀測到兩條分支指令/第一條是分支,第二條是直接跳轉,那么預測塊的大小是起始地址到終止地址之間的大小,終止地址是第二條分支或者跳轉指令的地址
情況3:如果一個預測塊中觀測到第一條分支指令就是直接跳轉,那么將直接跳轉的地址作為終止地址
TAGE:將起始地址作為TAGE的PC,進行預測,這個PC可以指向的是一條指令,也可以是一塊指令,這跟FTB的保存機制相關。
(2)預測時:
TAGE:?PC和分?歷史尋址多個分?歷史表,在多個命中的表項中優先挑選對應分?歷史最?的
結果作為最終結果。表項內實際為?飽和計數器,最?位確定最終跳轉?向。每個預測結果的meta
信息包含了預測所使?的預測表、當前的altpred結果等信息,會被寫?FTQ中,更新時會復?這些
信息完成更新,其中tag利?update通道中更新?PC、分?歷史計算,ctr更新時若在分配新表項,
則依據跳轉與否更新為4或3,否則基于現有ctr值增減。
3. 第三個周期(RAS、TAGE-SC)
TAGE-SC:利?PC和分?歷史尋址SC表,在TAGE給出的預測可信度不?時,反轉其預測結果。SC同樣
會將tageTakens、scUsed、scPreds、ctrs這類meta信息與預測結果?同傳遞寫?到FTQ。在更新
時,將根據是否wrbypass選擇原有ctr還是根據當前taken結果更新。此外全局的thresholds要在sc和
tage結果不?致時更新。







