模型十 聚類模型
一、含義聚類,就是將樣本劃分為由類似的對象組成的多個類的過程。聚類后,可以更加準確的在每個類中單獨使用統計模型進行估計、分析
一、含義
聚類,就是將樣本劃分為由類似的對象組成的多個類的過程。聚類后,可以更加準確的在每個類中單獨使用統計模型進行估計、分析或預測;也可以探究不同類之間的相關性和主要差異。分類是已知類別的,聚類未知。
二、算法
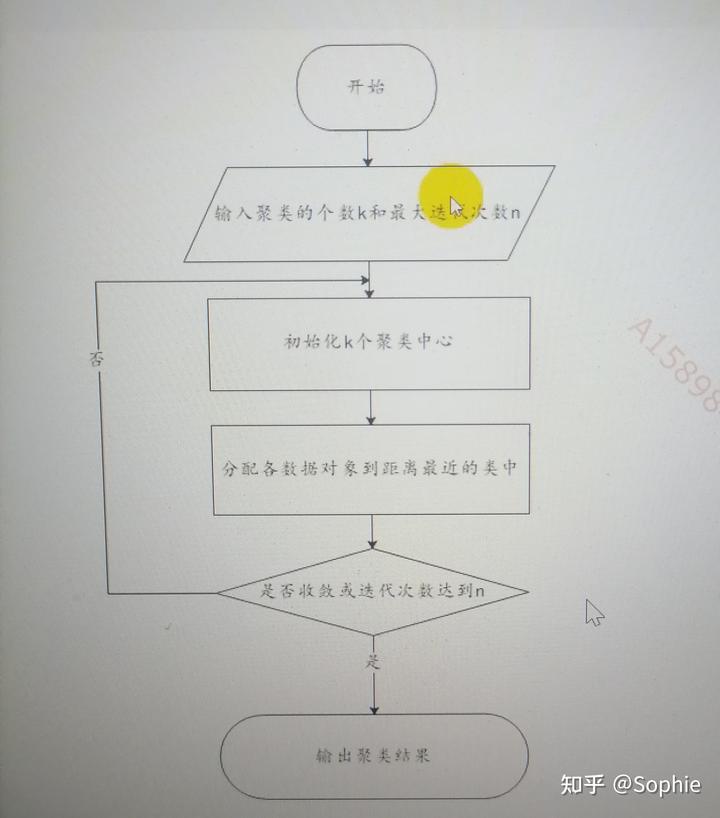
K - means 聚類的算法流程:
一、指定需要劃分的簇[ cu ]的個數 K 值(類的個數);
二、隨機地選擇 K 個數據對象作為初始的聚類中心(不一定要是我們的樣本點);
三、計算其余的各個數據對象到這 K 個初始聚類中心的距離,把數據對象劃歸到距離它最近的那個中心所處在的簇類中;
四、調整新類并且重新計算出新類的中心;
五、循環步驟三和四,看中心是否收斂(不變),如果收斂或達到迭代次數則停止循環;
六、結束。

在論文中可以畫圖表示步驟
三、算法評價
優點:
(1)算法簡單、快速。
(2)對處理大數據集,該算法是相對高效率的。
缺點:
(1)要求用戶必須事先給出要生成的簇的數目 k 。(2)對初值敏感。
(3)對于孤立點數據敏感。
K - means ++算法可解決2、3兩個缺點。
四、K - means ++算法
k - means ++算法選擇初始聚類中心的基本原則是:初始的聚類中心之間的相互距離要盡可能的遠。
算法描述如下:
(只對 K - means 算法"初始化 K 個聚類中心"這一步進行了優化)
步驟一:隨機選取一個樣本作為第一個聚類中心;
步驟二:計算每個樣本與當前已有聚類中心的最短距離(即與最近一個聚類中心的距離),這個值越大,表示被選取作為聚類中心的概率較大;最后,用輪盤法(依據概率大小來進行抽選)選出下一個聚類中心;
步驟三:重復步驟二,直到選出 K 個聚類中心。選出初始點后,就繼續使用標準的 K - means 算法了。
五、常見問題
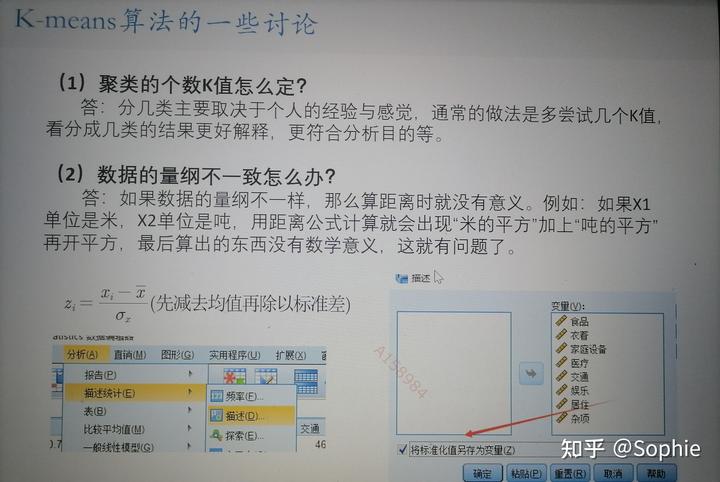
六、系統(層次)聚類
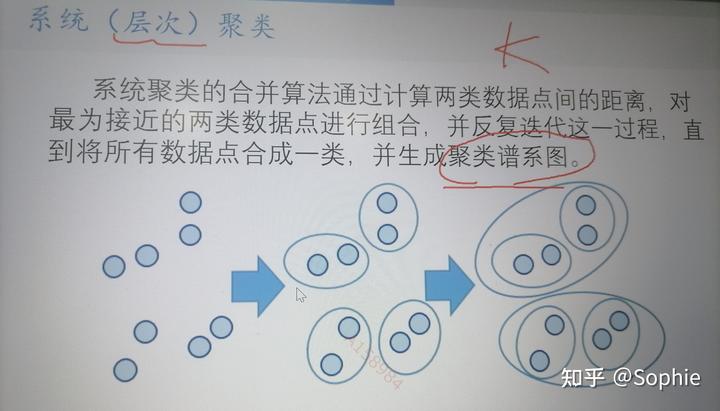
聚類的原則:距離近的樣本聚為一類

絕對值距離:適用于網狀道路
歐式距離:運用最廣泛,是Minkowskim距離的一個特例。
切比雪夫距離:運用十分少
馬氏距離:用的少
如果有網狀道路,用絕對值距離,其他一般用歐式距離。







組內平均法和組間平均分用的較多。聚類的方法多種多樣,只要能解釋出結果就行。
七、系統聚類的一個例子(以最短距離法為例)



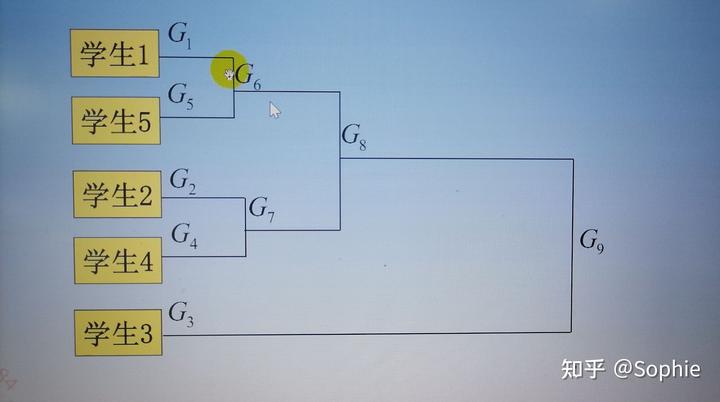

八、系統聚類需要注意的問題
1.對于一個實際問題要根據分類的目的來選取指標,指標選取的不同,分類結果一般也不同。
2.樣品間距離定義方式的不同,聚類結果一般也不同。
3.聚類方法的不同,聚類結果一般也不同(尤其是樣品特別多的時候)。最好能通過各種方法找出其中的共性。
4.要注意指標的量綱,量綱差別太大會導致聚類結果不合理。
5.聚類分析的結果可能不令人滿意,因為我們所做的是一個數學的處理,對于結果我們要找到一個合理的解釋。
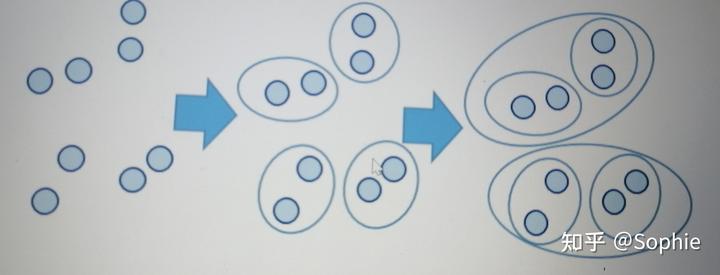
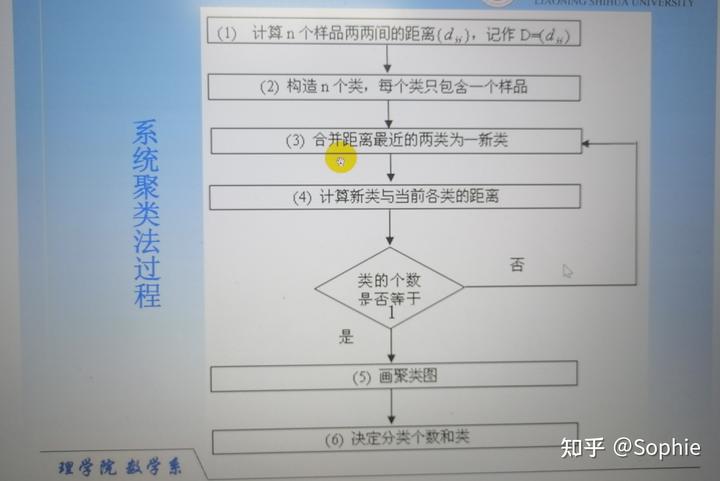
九、系統聚類算法流程
一、將每個對象看作一類,計算兩兩之間的最小距離;
二、將距離最小的兩個類合并成一個新類;
三、重新計算新類與所有類之間的距離;
四、重復二三兩步,直到所有類最后合并成一類;
五、結束。
在spass運行中,為了方便解釋,最好k≤5
十、系統聚類中如何確定k的數量——肘部法則

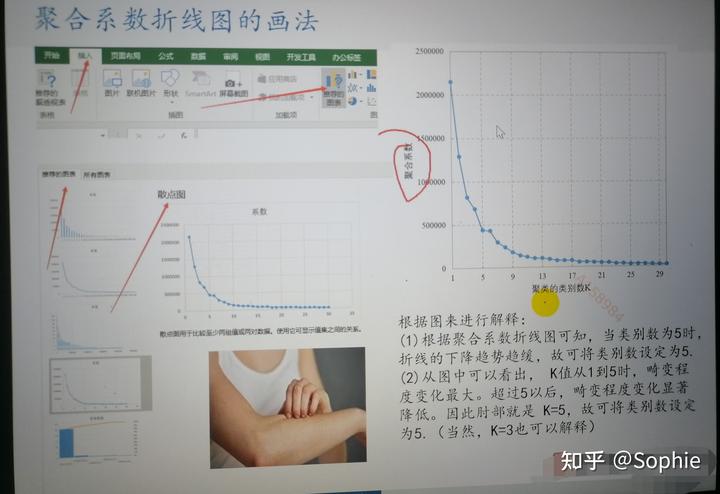
k越大,J(聚合系數越小),所以聚合系數折線圖是遞減的。
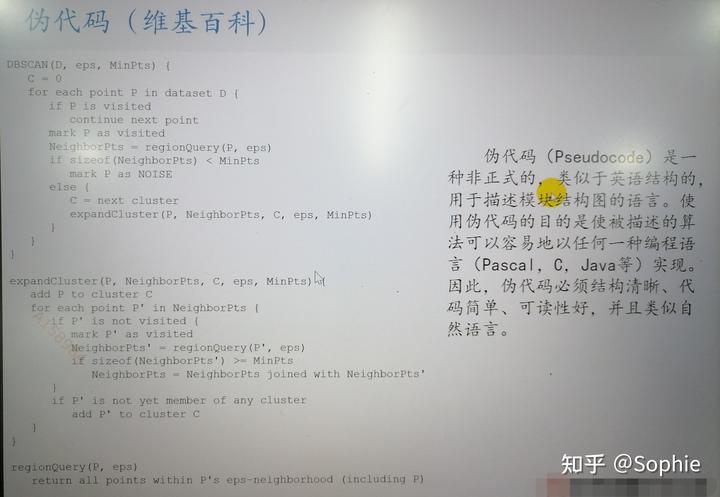
十一、DBSCAN算法
DBSCAN ( Density - based spatial clustering of applications with noise )(具有噪聲的基于密度的聚類算法)是 Martin Ester , Hans - PeterKriegel 等人于1996年提出的一種基于密度的聚類方法,聚類前不需要預先指定聚類的個數,生成的簇的個數不定(和數據有關)。該算法利用基于密度的聚類的概念,即要求聚類空間中的一定區域內所包含對象(點或其他空間對象)的數目不小于某一給定閾值。該方法能在具有噪聲的空間數據庫中發現任意形狀的簇,可將密度足夠大的相鄰區域連接,能有效處理異常數據。
K-means聚類算法和系統聚類算法是基于距離,而DBSCAN是基于密度
1.基本概念
DBSCAN 算法將數據點分為三類:
·核心點:在半徑 Eps 內含有不少于 MinPts 數目的點
.邊界點:在半徑 Eps 內點的數量小于 MinPts ,但是落在核心點的鄰域內
·噪音點:既不是核心點也不是邊界點的點
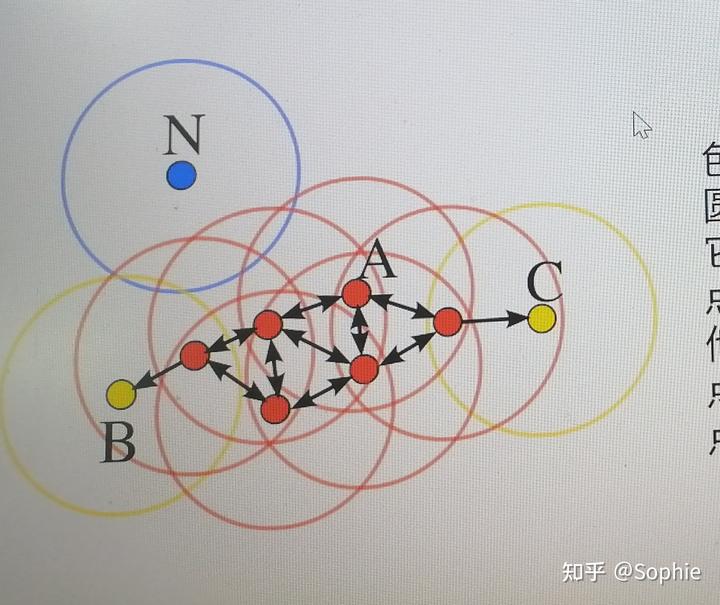
在這幅圖里, MinPts =4,點 A 和其他紅色點是核心點,因為它們的 鄰域(圖中紅色圓圈)里包含最少4個點(包括自己),由于它們之間相互相可達,它們形成了一個聚類。點 B 和點 C 不是核心點,但它們可由 A 經其他核心點可達,所以也和 A 屬于同一個聚類。點 N 是局外點,它既不是核心點,又不由其他點可達。
2.實現過程
Matlab 代碼
Matlab 官網推薦下載的代碼:
https://ww2.mathworks.cn/matlabcentral/fileexchange/52905-dbscan-clustering-algorithm
% Copyright ( c )2015, Yarpiz (http://www.yarpiz.com)
% All rights reserved . Please read the " license . txt " for license terms .
%
% Project Code :YPML110
% Project Title : Implementation of DBSCAN Clustering in MATLAB % Publisher : Yarpiz (http://www.yarpiz.com)
%
% Developer : S . Mostapha Kalami Heris ( Member of Yarpiz Team )%
% Contact Info:sm.kalami@gmail.com,info@yarpiz.com
3.優缺點
優點:
1.基于密度定義,能處理任意形狀和大小的簇;
2.可在聚類的同時發現異常點;
3.與 K - means 比較起來,不需要輸入要劃分的聚類個數。
缺點:
1.對輸入參數 E 和 Minpts 敏感,確定參數困難;
2.由于 DBSCAN 算法中,變量和 Minpts 是全局唯一的,當聚類的密度不均勻時,聚類距離相差很大時,聚類質量差;
3.當數據量大時,計算密度單元的計算復雜度大。
建議:
只有兩個指標,且你做出散點圖后發現數據表現得很" DBSCAN ",這時候你再用 DNSCAN 進行聚類。
其他情況下,全部使用系統聚類吧。
K - means 也可以用,不過用了的話你論文上可寫的東西比較少。







